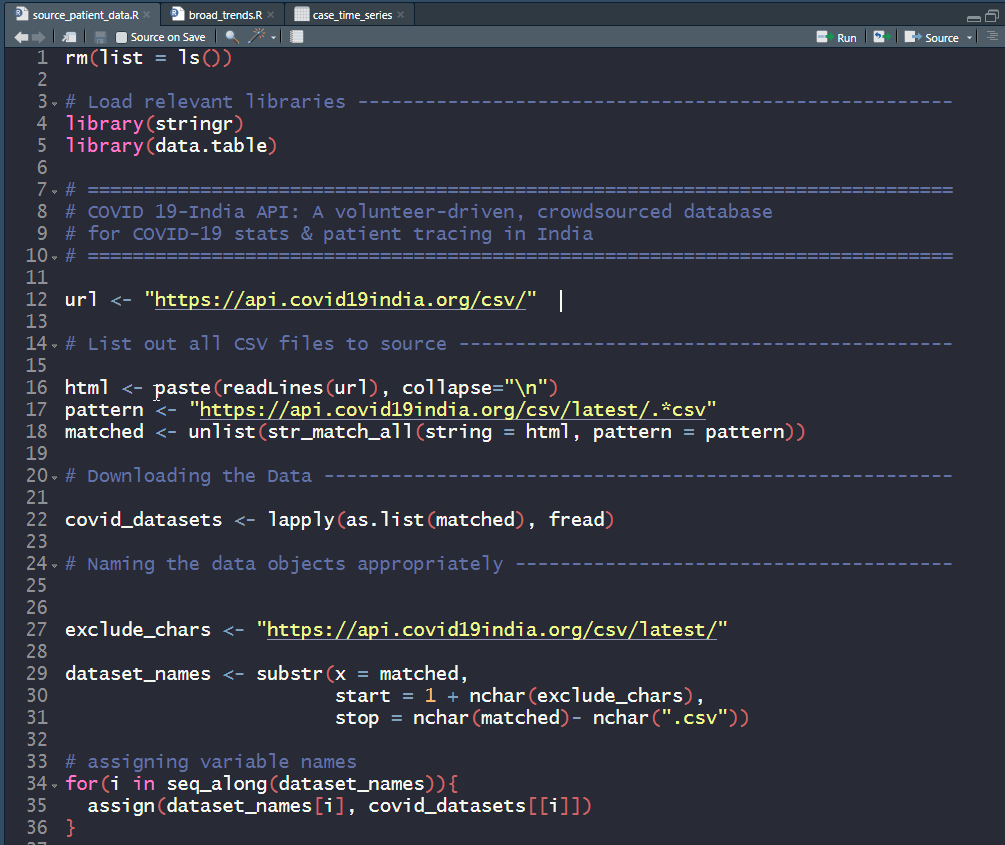
This is a very short post that will be very useful to help you quickly set up your COVID-19 datasets. I’m sharing code at the end of this post that scrapes through all CSV datasets made available by COVID19-India API.
We have exposed all the crowdsourced patient details, travel history (published by authorities) and statewise trends in this live API : https://t.co/tNyhpPYTJD A shout-out to all Data Analysts, Planners and Enthusiasts to use this data for helping the containment efforts. @_mekin
Copy paste this standalone script into your R environment and get going!
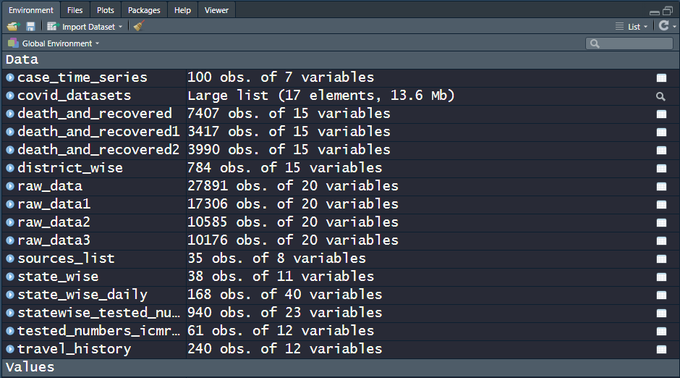
There are 15+ CSV files on the India COVID-19 API website. raw_data3 is actually a live dataset and more can be expected in the days to come, which is why a script that automates the data sourcing comes in handy. Snapshot of the file names and the data dimensions as of today, 100 days since the first case was recorded in the state of Kerala —
My own analysis of the data and predictions are work-in-progress, going into a Github repo. Execute the code below and get started analyzing the data and fighting COVID-19!
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This post comes out of the blue, nearly 2 years since my last one. I realize I’ve been lazy, so here’s hoping I move from an inertia of rest to that of motion, implying, regular and (hopefully) relevant posts. I also chanced upon some wisdom while scrolling through my Twitter feed:
This blog post in particular was meant to be a reminder to myself and other R users that the much used lm() function in R (for fitting linear models) can be replaced with some handy matrix operations to obtain regression coefficients, their standard errors and other goodness-of-fit stats printed out when summary() is called on an lm object.
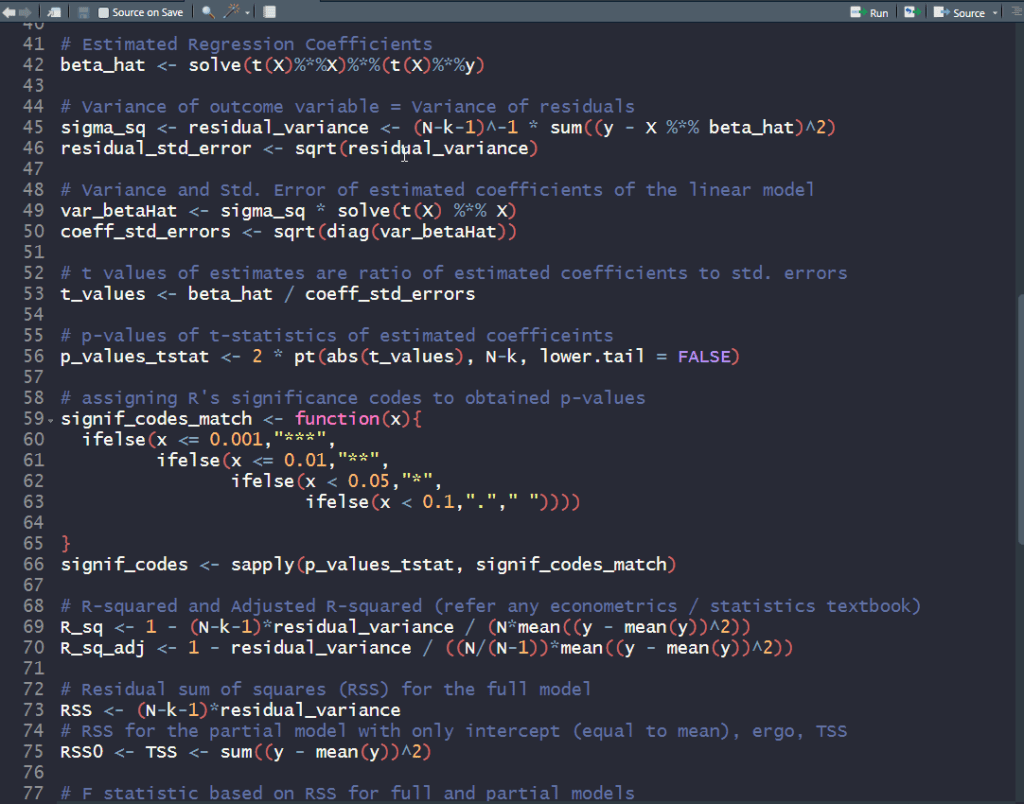
Linear regression can be formulated mathematically as follows: ,
is the outcome variable and is the data matrix of independent predictor variables (including a vector of ones corresponding to the intercept). The ordinary least squares (OLS) estimate for the vector of coefficients is:
The covariance matrix can be obtained with some handy matrix operations:
given that
The standard errors of the coefficients are basically and with these, one can compute the t-statistics and their corresponding p-values.
Lastly, the F-statistic and its corresponding p-value can be calculated after computing the two residual sum of squares (RSS) statistics:
– for the full model with all predictors
– for the partial model () with the outcome observed mean as estimated outcome
I wrote some R code to construct the output from summarizing lm objects, using all the math spewed thus far. The data used for this exercise is available in R, and comprises of standardized fertility measures and socio-economic indicators for each of 47 French-speaking provinces of Switzerland from 1888. Try it out and see for yourself the linear algebra behind linear regression.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
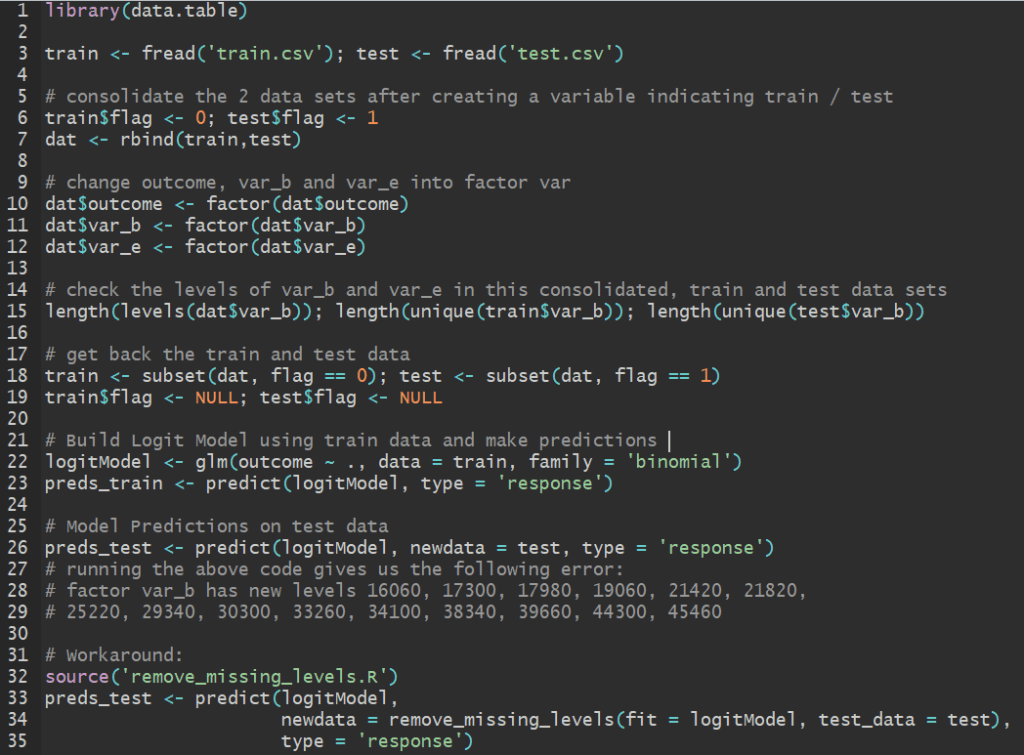
Let’s say you have data containing a categorical variable with 50 levels. When you divide the data into train and test sets, chances are you don’t have all 50 levels featuring in your training set.
This often happens when you divide the data set into train and test sets according to the distribution of the outcome variable. In doing so, chances are that our explanatory categorical variable might not be distributed exactly the same way in train and test sets – so much so that certain levels of this categorical variable are missing from the training set. The more levels there are to a categorical variable, it gets difficult for that variable to be similarly represented upon splitting the data.
Take for instance this example data set (train.csv + test.csv) which contains a categorical variable var_b that takes 349 unique levels. Our train data has 334 of these levels – on which the model is built – and hence 15 levels are excluded from our trained model. If you try making predictions on the test set with this model in R, it throws an error: factor var_b has new levels 16060, 17300, 17980, 19060, 21420, 21820,
25220, 29340, 30300, 33260, 34100, 38340, 39660, 44300, 45460
If you’ve used R to model generalized linear class of models such as linear, logit or probit models, then chances are you’ve come across this problem – especially when you’re validating your trained model on test data.
The workaround to this problem is in the form of a function, remove_missing_levels that I found here written by pat-s. You need magrittr library installed and it can only work on lm, glm and glmmPQL objects.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Once you’ve sourced the above function in R, you can seamlessly proceed with using your trained model to make predictions on the test set. The code below demonstrates this for the data set shared above. You can find these codes in one of my github repos and try it out yourself.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Through this post, I’m sharing Python code implementing the median of medians algorithm, an algorithm that resembles quickselect, differing only in the way in which the pivot is chosen, i.e, deterministically, instead of at random.
Its best case complexity is O(n) and worst case complexity O(nlog2n)
I don’t have a formal education in CS, and came across this algorithm while going through Tim Roughgarden’s Coursera MOOC on the design and analysis of algorithms. Check out my implementation in Python.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
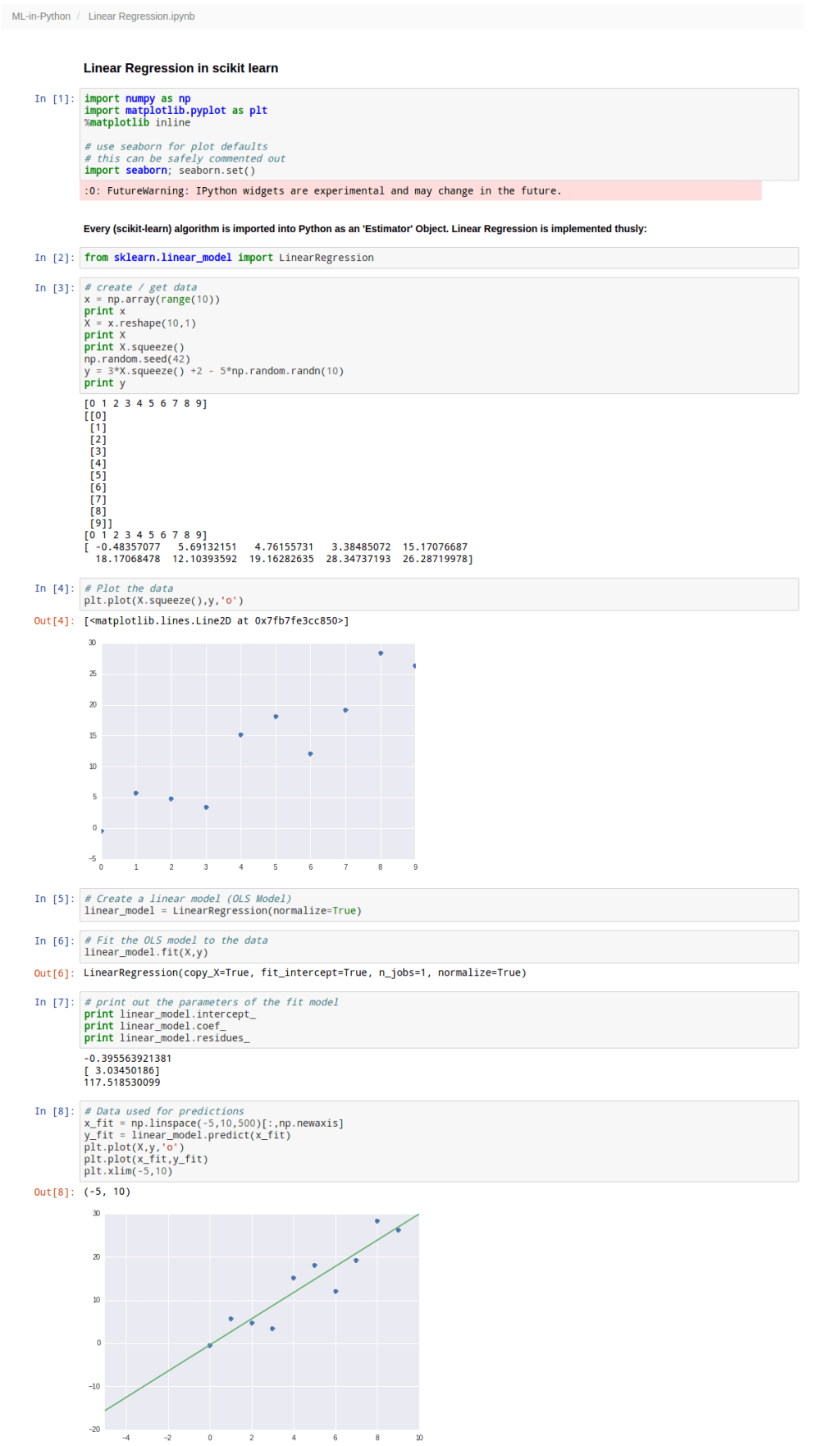
Here’s a quick example case for implementing one of the simplest of learning algorithms in any machine learning toolbox – Linear Regression. You can download the IPython / Jupyter notebook here so as to play around with the code and try things out yourself.
I’m doing a series of posts on scikit-learn. Its documentation is vast, so unless you’re willing to search for a needle in a haystack, you’re better off NOT jumping into the documentation right away. Instead, knowing chunks of code that do the job might help.
Edit: This post is in its infancy. Work is still ongoing as far as deriving insight from the data is concerned. More content and economic insight is expected to be added to this post as and when progress is made in that direction.
This is an attempt to detect structural breaks in China’s FX regime using Frenkel Wei regression methodology (this was later improved by Perron and Bai). I came up with the motivation to check for these structural breaks while attending a guest lecture on FX regimes by Dr. Ajay Shah delivered at IGIDR. This is work that I and two other classmates are working on as a term paper project under the supervision of Dr. Rajeswari Sengupta.
The code below can be replicated and run as is, to get same results.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
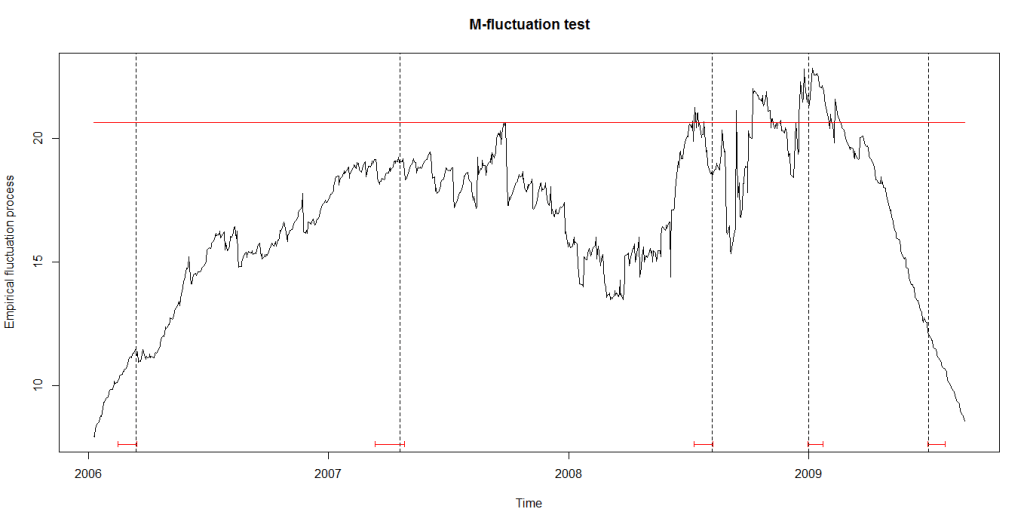
As can be seen in the figure below, the structural breaks correspond to the vertical bars. We are still working on understanding the motivations of China’s central bank in varying the degree of the managed float exchange rate.
EDIT (May 16, 2016):
The code above uses data provided by the package itself. If you wished to replicate this analysis on data after 2010, you will have to use your own data. We used Quandl, which lets you get 10 premium datasets for free. An API key (for only 10 calls on premium datasets) is provided if you register there. Foreign exchange rate data (2000 onward till date) apparently, is premium data. You can find these here.
Here are the (partial) results and code to work the same methodology on the data from 2010 to 2016:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
We got breaks in 2010 and in 2015 (when China’s stock markets crashed). We would have hoped for more breaks (we can still get them), but that would depend on the parameters chosen for our regression.
This happens to be my 50th blog post – and my blog is 8 months old.
🙂
This post is the third and last post in in a series of posts (Part 1 – Part 2) on data manipulation with dlpyr. Note that the objects in the code may have been defined in earlier posts and the code in this post is in continuation with code from the earlier posts.
Although datasets can be manipulated in sophisticated ways by linking the 5 verbs of dplyr in conjunction, linking verbs together can be a bit verbose.
Creating multiple objects, especially when working on a large dataset can slow you down in your analysis. Chaining functions directly together into one line of code is difficult to read. This is sometimes called the Dagwood sandwich problem: you have too much filling (too many long arguments) between your slices of bread (parentheses). Functions and arguments get further and further apart.
The %>% operator allows you to extract the first argument of a function from the arguments list and put it in front of it, thus solving the Dagwood sandwich problem.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
group_by() defines groups within a data set. Its influence becomes clear when calling summarise() on a grouped dataset. Summarizing statistics are calculated for the different groups separately.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
group_by() can also be combined with mutate(). When you mutate grouped data, mutate() will calculate the new variables independently for each group. This is particularly useful when mutate() uses the rank() function, that calculates within group rankings. rank() takes a group of values and calculates the rank of each value within the group, e.g.
rank(c(21, 22, 24, 23))
has output
[1] 1 2 4 3
As with arrange(), rank() ranks values from the largest to the smallest and this behaviour can be reversed with the desc() function.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Note that this post is in continuation with Part 1 of this series of posts on data manipulation with dplyr in R. The code in this post carries forward from the variables / objects defined in Part 1.
In the previous post, I talked about how dplyr provides a grammar of sorts to manipulate data, and consists of 5 verbs to do so:
The 5 verbs of dplyr select – removes columns from a dataset filter – removes rows from a dataset arrange – reorders rows in a dataset mutate – uses the data to build new columns and values summarize – calculates summary statistics
I went on to discuss examples using select() and mutate(). Let’s now talk about filter(). R comes with a set of logical operators that you can use inside filter(). These operators are: x < y,TRUE if x is less than y x <= y, TRUE if x is less than or equal to y x == y, TRUE if x equals y x != y, TRUE if x does not equal y x >= y, TRUE if x is greater than or equal to y x > y, TRUE if x is greater than y x %in% c(a, b, c), TRUE if x is in the vector c(a, b, c)
The following call, for example, filters df such that only the observations where the variable a is greater than the variable b: filter(df, a > b)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Combining tests using boolean operators
R also comes with a set of boolean operators that you can use to combine multiple logical tests into a single test. These include & (and), | (or), and ! (not). Instead of using the & operator, you can also pass several logical tests to filter(), separated by commas. The following calls equivalent:
filter(df, a > b & c > d) filter(df, a > b, c > d)
The is.na() will also come in handy very often. This expression, for example, keeps the observations in df for which the variable x is not NA:
filter(df, !is.na(x))
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Arranging Data arrange() can be used to rearrange rows according to any type of data. If you pass arrange() a character variable, R will rearrange the rows in alphabetical order according to values of the variable. If you pass a factor variable, R will rearrange the rows according to the order of the levels in your factor (running levels() on the variable reveals this order).
By default, arrange() arranges the rows from smallest to largest. Rows with the smallest value of the variable will appear at the top of the data set. You can reverse this behaviour with the desc() function. arrange() will reorder the rows from largest to smallest values of a variable if you wrap the variable name in desc() before passing it to arrange()
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
summarise(), the last of the 5 verbs, follows the same syntax as mutate(), but the resulting dataset consists of a single row instead of an entire new column in the case of mutate().
In contrast to the four other data manipulation functions, summarise() does not return an altered copy of the dataset it is summarizing; instead, it builds a new dataset that contains only the summarizing statistics.
Note:summarise() and summarize() both work the same!
You can use any function you like in summarise(), so long as the function can take a vector of data and return a single number. R contains many aggregating functions. Here are some of the most useful:
min(x) – minimum value of vector x. max(x) – maximum value of vector x. mean(x) – mean value of vector x. median(x) – median value of vector x. quantile(x, p) – pth quantile of vector x. sd(x) – standard deviation of vector x. var(x) – variance of vector x. IQR(x) – Inter Quartile Range (IQR) of vector x. diff(range(x)) – total range of vector x.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
dplyr provides several helpful aggregate functions of its own, in addition to the ones that are already defined in R. These include:
first(x) – The first element of vector x. last(x) – The last element of vector x. nth(x, n) – The nth element of vector x. n() – The number of rows in the data.frame or group of observations that summarise() describes. n_distinct(x) – The number of unique values in vector x
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This would be it for Part-2 of this series of posts on data manipulation with dplyr. Part 3 would focus on the pipe operator, Group_by and working with databases.
dplyr is one of the packages in R that makes R so loved by data scientists. It has three main goals:
Identify the most important data manipulation tools needed for data analysis and make them easy to use in R.
Provide blazing fast performance for in-memory data by writing key pieces of code in C++.
Use the same code interface to work with data no matter where it’s stored, whether in a data frame, a data table or database.
Introduction to the dplyr package and the tbl class
This post is mostly about code. If you’re interested in learning dplyr I recommend you type in the commands line by line on the R console to see first hand what’s happening.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Select and mutate dplyr provides grammar for data manipulation apart from providing data structure. The grammar is built around 5 functions (also referred to as verbs) that do the basic tasks of data manipulation.
The 5 verbs of dplyr select – removes columns from a dataset filter – removes rows from a dataset arrange – reorders rows in a dataset mutate – uses the data to build new columns and values summarize – calculates summary statistics
dplyr functions do not change the dataset. They return a new copy of the dataset to use.
To answer the simple question whether flight delays tend to shrink or grow during a flight, we can safely discard a lot of the variables of each flight. To select only the ones that matter, we can use select()
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
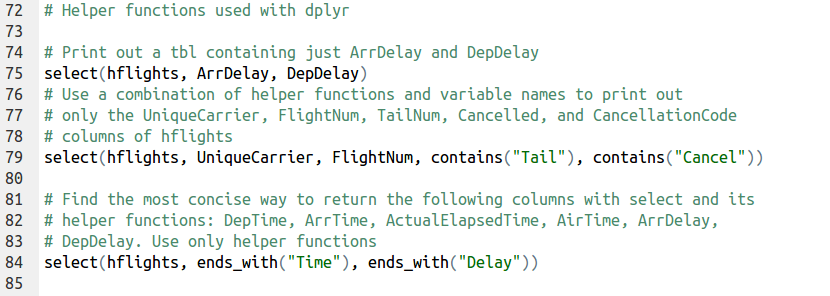
dplyr comes with a set of helper functions that can help you select variables. These functions find groups of variables to select, based on their names. Each of these works only when used inside of select()
starts_with(“X”): every name that starts with “X”
ends_with(“X”): every name that ends with “X”
contains(“X”): every name that contains “X”
matches(“X”): every name that matches “X”, where “X” can be a regular expression
num_range(“x”, 1:5): the variables named x01, x02, x03, x04 and x05
one_of(x): every name that appears in x, which should be a character vector
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
In order to appreciate the usefulness of dplyr, here are some comparisons between base R and dplyr
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
mutate() is the second of the five data manipulation functions. mutate() creates new columns which are added to a copy of the dataset.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
So far we have added variables to hflights one at a time, but we can also use mutate() to add multiple variables at once.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
 ,
,
 is the
is the  outcome variable and
outcome variable and  is the
is the  data matrix of independent predictor variables (including a vector of ones corresponding to the intercept). The ordinary least squares (OLS) estimate for the vector of coefficients
data matrix of independent predictor variables (including a vector of ones corresponding to the intercept). The ordinary least squares (OLS) estimate for the vector of coefficients  is:
is:


 and with these, one can compute the t-statistics and their corresponding p-values.
and with these, one can compute the t-statistics and their corresponding p-values. – for the full model with all predictors
– for the full model with all predictors – for the partial model (
– for the partial model (![\mathbf{y} = \mathbf{\mu} + \mathbf{\nu}; \mathbf{\mu} = \mathop{\mathbb{E}}[\mathbf{y}]; \mathbf{\nu} \sim N(0, \sigma_0^2 \mathbf{I})](https://s0.wp.com/latex.php?latex=%5Cmathbf%7By%7D+%3D+%5Cmathbf%7B%5Cmu%7D+%2B+%5Cmathbf%7B%5Cnu%7D%3B+%5Cmathbf%7B%5Cmu%7D+%3D+%5Cmathop%7B%5Cmathbb%7BE%7D%7D%5B%5Cmathbf%7By%7D%5D%3B+%5Cmathbf%7B%5Cnu%7D+%5Csim+N%280%2C+%5Csigma_0%5E2+%5Cmathbf%7BI%7D%29+&bg=ffffff&fg=000&s=1&c=20201002) ) with the outcome observed mean as estimated outcome
) with the outcome observed mean as estimated outcome