Let’s say you have data containing a categorical variable with 50 levels. When you divide the data into train and test sets, chances are you don’t have all 50 levels featuring in your training set.
This often happens when you divide the data set into train and test sets according to the distribution of the outcome variable. In doing so, chances are that our explanatory categorical variable might not be distributed exactly the same way in train and test sets – so much so that certain levels of this categorical variable are missing from the training set. The more levels there are to a categorical variable, it gets difficult for that variable to be similarly represented upon splitting the data.
Take for instance this example data set (train.csv + test.csv) which contains a categorical variable var_b that takes 349 unique levels. Our train data has 334 of these levels – on which the model is built – and hence 15 levels are excluded from our trained model. If you try making predictions on the test set with this model in R, it throws an error:
factor var_b has new levels 16060, 17300, 17980, 19060, 21420, 21820,
25220, 29340, 30300, 33260, 34100, 38340, 39660, 44300, 45460
If you’ve used R to model generalized linear class of models such as linear, logit or probit models, then chances are you’ve come across this problem – especially when you’re validating your trained model on test data.
The workaround to this problem is in the form of a function, remove_missing_levels that I found here written by pat-s. You need magrittr library installed and it can only work on lm, glm and glmmPQL objects.
| remove_missing_levels <- function(fit, test_data) { | |
| library(magrittr) | |
| # https://stackoverflow.com/a/39495480/4185785 | |
| # drop empty factor levels in test data | |
| test_data %>% | |
| droplevels() %>% | |
| as.data.frame() -> test_data | |
| # 'fit' object structure of 'lm' and 'glmmPQL' is different so we need to | |
| # account for it | |
| if (any(class(fit) == "glmmPQL")) { | |
| # Obtain factor predictors in the model and their levels | |
| factors <- (gsub("[-^0-9]|as.factor|\\(|\\)", "", | |
| names(unlist(fit$contrasts)))) | |
| # do nothing if no factors are present | |
| if (length(factors) == 0) { | |
| return(test_data) | |
| } | |
| map(fit$contrasts, function(x) names(unmatrix(x))) %>% | |
| unlist() -> factor_levels | |
| factor_levels %>% str_split(":", simplify = TRUE) %>% | |
| extract(, 1) -> factor_levels | |
| model_factors <- as.data.frame(cbind(factors, factor_levels)) | |
| } else { | |
| # Obtain factor predictors in the model and their levels | |
| factors <- (gsub("[-^0-9]|as.factor|\\(|\\)", "", | |
| names(unlist(fit$xlevels)))) | |
| # do nothing if no factors are present | |
| if (length(factors) == 0) { | |
| return(test_data) | |
| } | |
| factor_levels <- unname(unlist(fit$xlevels)) | |
| model_factors <- as.data.frame(cbind(factors, factor_levels)) | |
| } | |
| # Select column names in test data that are factor predictors in | |
| # trained model | |
| predictors <- names(test_data[names(test_data) %in% factors]) | |
| # For each factor predictor in your data, if the level is not in the model, | |
| # set the value to NA | |
| for (i in 1:length(predictors)) { | |
| found <- test_data[, predictors[i]] %in% model_factors[ | |
| model_factors$factors == predictors[i], ]$factor_levels | |
| if (any(!found)) { | |
| # track which variable | |
| var <- predictors[i] | |
| # set to NA | |
| test_data[!found, predictors[i]] <- NA | |
| # drop empty factor levels in test data | |
| test_data %>% | |
| droplevels() -> test_data | |
| # issue warning to console | |
| message(sprintf(paste0("Setting missing levels in '%s', only present", | |
| " in test data but missing in train data,", | |
| " to 'NA'."), | |
| var)) | |
| } | |
| } | |
| return(test_data) | |
| } |
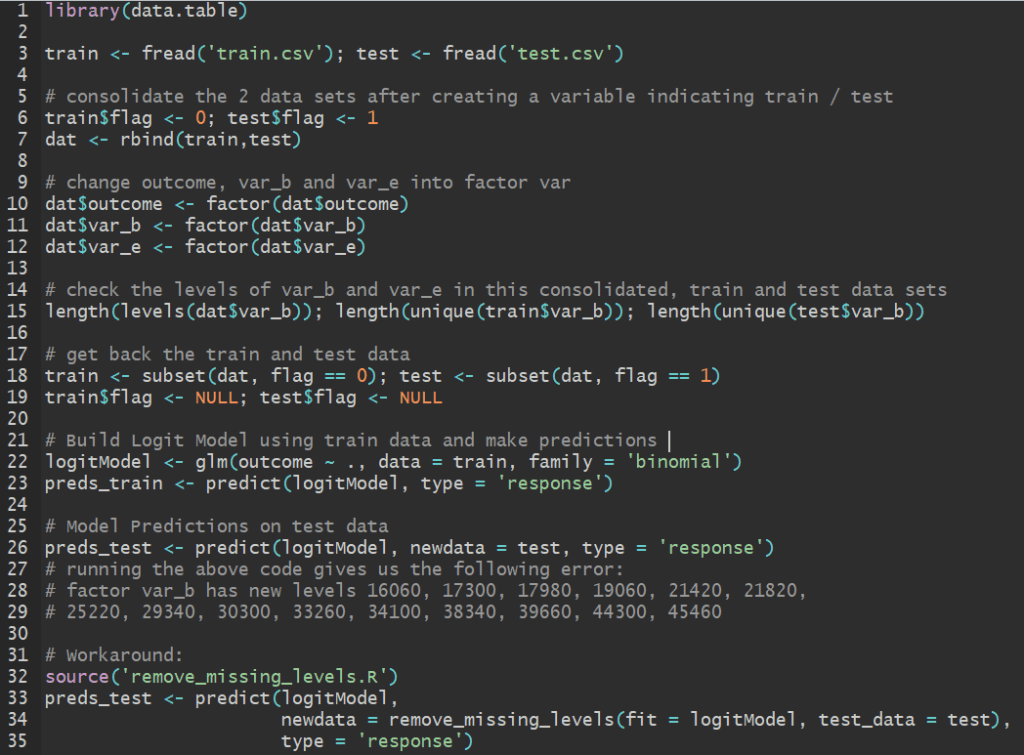
Once you’ve sourced the above function in R, you can seamlessly proceed with using your trained model to make predictions on the test set. The code below demonstrates this for the data set shared above. You can find these codes in one of my github repos and try it out yourself.
| library(data.table) | |
| train <- fread('train.csv'); test <- fread('test.csv') | |
| # consolidate the 2 data sets after creating a variable indicating train / test | |
| train$flag <- 0; test$flag <- 1 | |
| dat <- rbind(train,test) | |
| # change outcome, var_b and var_e into factor var | |
| dat$outcome <- factor(dat$outcome) | |
| dat$var_b <- factor(dat$var_b) | |
| dat$var_e <- factor(dat$var_e) | |
| # check the levels of var_b and var_e in this consolidated, train and test data sets | |
| length(levels(dat$var_b)); length(unique(train$var_b)); length(unique(test$var_b)) | |
| # get back the train and test data | |
| train <- subset(dat, flag == 0); test <- subset(dat, flag == 1) | |
| train$flag <- NULL; test$flag <- NULL | |
| # Build Logit Model using train data and make predictions | |
| logitModel <- glm(outcome ~ ., data = train, family = 'binomial') | |
| preds_train <- predict(logitModel, type = 'response') | |
| # Model Predictions on test data | |
| preds_test <- predict(logitModel, newdata = test, type = 'response') | |
| # running the above code gives us the following error: | |
| # factor var_b has new levels 16060, 17300, 17980, 19060, 21420, 21820, | |
| # 25220, 29340, 30300, 33260, 34100, 38340, 39660, 44300, 45460 | |
| # Workaround: | |
| source('remove_missing_levels.R') | |
| preds_test <- predict(logitModel, | |
| newdata = remove_missing_levels(fit = logitModel, test_data = test), | |
| type = 'response') |