|
#!/usr/bin/env |
|
|
|
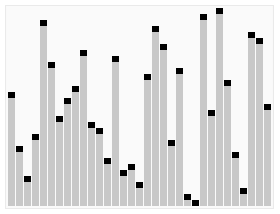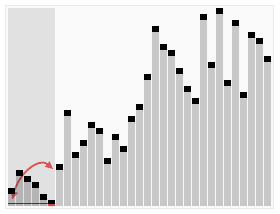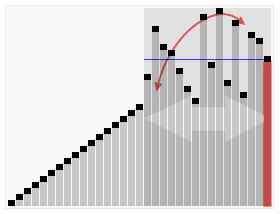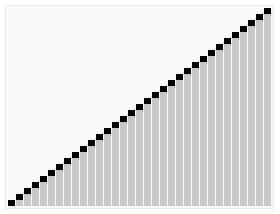
# Case I |
|
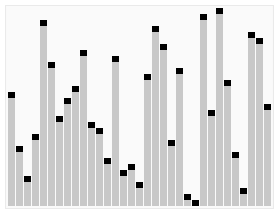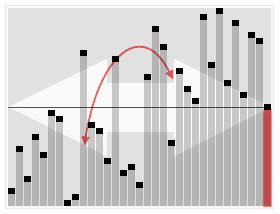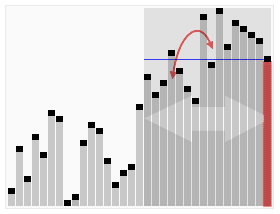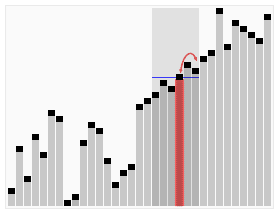
# First element of the unsorted array is chosen as pivot element for sorting using Quick Sort |
|
|
|
|
|
def countComparisonsWithFirst(x): |
|
""" Counts number of comparisons while using Quick Sort with first element of unsorted array as pivot """ |
|
global count_pivot_first |
|
if len(x) == 1 or len(x) == 0: |
|
return x |
|
else: |
|
count_pivot_first += len(x)-1 |
|
i = 0 |
|
for j in range(len(x)-1): |
|
if x[j+1] < x[0]: |
|
x[j+1],x[i+1] = x[i+1], x[j+1] |
|
i += 1 |
|
x[0],x[i] = x[i],x[0] |
|
first_part = countComparisonsWithFirst(x[:i]) |
|
second_part = countComparisonsWithFirst(x[i+1:]) |
|
first_part.append(x[i]) |
|
return first_part + second_part |
|
|
|
# Case II |
|
# Last element of the unsorted array is chosen as pivot element for sorting using Quick Sort |
|
|
|
def countComparisonsWithLast(x): |
|
""" Counts number of comparisons while using Quick Sort with last element of unsorted array as pivot """ |
|
global count_pivot_last |
|
if len(x) == 1 or len(x) == 0: |
|
return x |
|
else: |
|
count_pivot_last += len(x)-1 |
|
x[0],x[-1] = x[-1],x[0] |
|
i = 0 |
|
for j in range(len(x)-1): |
|
if x[j+1] < x[0]: |
|
x[j+1],x[i+1] = x[i+1], x[j+1] |
|
i += 1 |
|
x[0],x[i] = x[i],x[0] |
|
first_part = countComparisonsWithLast(x[:i]) |
|
second_part = countComparisonsWithLast(x[i+1:]) |
|
first_part.append(x[i]) |
|
return first_part + second_part |
|
|
|
# Case III |
|
# Median-of-three method used to choose pivot element for sorting using Quick Sort |
|
|
|
def middle_index(x): |
|
""" Returns the index of the middle element of an array """ |
|
if len(x) % 2 == 0: |
|
middle_index = len(x)/2 – 1 |
|
else: |
|
middle_index = len(x)/2 |
|
return middle_index |
|
|
|
def median_index(x,i,j,k): |
|
""" Returns the median index of three when passed an array and indices of any 3 elements of that array """ |
|
if (x[i]-x[j])*(x[i]-x[k]) < 0: |
|
return i |
|
elif (x[j]-x[i])*(x[j]-x[k]) < 0: |
|
return j |
|
else: |
|
return k |
|
|
|
def countComparisonsMedianOfThree(x): |
|
""" Counts number of comparisons while using Quick Sort with median-of-three element is chosen as pivot """ |
|
global count_pivot_median |
|
if len(x) == 1 or len(x) == 0: |
|
return x |
|
else: |
|
count_pivot_median += len(x)-1 |
|
k = median_index(x, 0, middle_index(x), -1) |
|
if k != 0: x[0], x[k] = x[k], x[0] |
|
i = 0 |
|
for j in range(len(x)-1): |
|
if x[j+1] < x[0]: |
|
x[j+1],x[i+1] = x[i+1], x[j+1] |
|
i += 1 |
|
x[0],x[i] = x[i],x[0] |
|
first_part = countComparisonsMedianOfThree(x[:i]) |
|
second_part = countComparisonsMedianOfThree(x[i+1:]) |
|
first_part.append(x[i]) |
|
return first_part + second_part |
|
|
|
##################################################################### |
|
# initializing counts |
|
count_pivot_first = 0; count_pivot_last = 0; count_pivot_median = 0 |
|
|
|
##################################################################### |
|
# Cast I |
|
# Read the contents of the file into a Python list |
|
NUMLIST_FILENAME = "QuickSort_List.txt" |
|
inFile = open(NUMLIST_FILENAME, 'r') |
|
|
|
with inFile as f: numList = [int(integers.strip()) for integers in f.readlines()] |
|
# call functions to count comparisons |
|
countComparisonsWithFirst(numList) |
|
|
|
##################################################################### |
|
# Read the contents of the file into a Python list |
|
NUMLIST_FILENAME = "QuickSort_List.txt" |
|
inFile = open(NUMLIST_FILENAME, 'r') |
|
|
|
with inFile as f: numList = [int(integers.strip()) for integers in f.readlines()] |
|
# call functions to count comparisons |
|
countComparisonsWithLast(numList) |
|
|
|
##################################################################### |
|
# Read the contents of the file into a Python list |
|
NUMLIST_FILENAME = "QuickSort_List.txt" |
|
inFile = open(NUMLIST_FILENAME, 'r') |
|
|
|
with inFile as f: numList = [int(integers.strip()) for integers in f.readlines()] |
|
# call functions to count comparisons |
|
countComparisonsMedianOfThree(numList) |
|
##################################################################### |
|
|
|
print count_pivot_first, count_pivot_last, count_pivot_median |