Through this post, I’m sharing Python code implementing the median of medians algorithm, an algorithm that resembles quickselect, differing only in the way in which the pivot is chosen, i.e, deterministically, instead of at random.
Its best case complexity is O(n) and worst case complexity O(nlog2n)
I don’t have a formal education in CS, and came across this algorithm while going through Tim Roughgarden’s Coursera MOOC on the design and analysis of algorithms. Check out my implementation in Python.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I’ve enrolled in Stanford Professor Tim Roughgarden’s Coursera MOOC on the design and analysis of algorithms, and while he covers the theory and intuition behind the algorithms in a surprising amount of detail, we’re left to implement them in a programming language of our choice.
And I’m ging to post Python code for all the algorithms covered during the course!
The Karatsuba Multiplication Algorithm
Karatsuba’s algorithm reduces the multiplication of two n-digit numbers to at most single-digit multiplications in general (and exactly when n is a power of 2). Although the familiar grade school algorithm for multiplying numbers is how we work through multiplication in our day-to-day lives, it’s slower () in comparison, but only on a computer, of course!
Here’s how the grade school algorithm looks: (The following slides have been taken from Tim Roughgarden’s notes. They serve as a good illustration. I hope he doesn’t mind my sharing them.)
…and this is how Karatsuba Multiplication works on the same problem:
A More General Treatment
Let and be represented as -digit strings in some base. For any positive integer less than , one can write the two given numbers as
,
where and are less than . The product is then
where
These formulae require four multiplications, and were known to Charles Babbage. Karatsuba observed that can be computed in only three multiplications, at the cost of a few extra additions. With and as before we can calculate
which holds since
A more efficient implementation of Karatsuba multiplication can be set as , where .
Example
To compute the product of 12345 and 6789, choose B = 10 and m = 3. Then we decompose the input operands using the resulting base (Bm = 1000), as:
12345 = 12 · 1000 + 345
6789 = 6 · 1000 + 789
Only three multiplications, which operate on smaller integers, are used to compute three partial results:
We get the result by just adding these three partial results, shifted accordingly (and then taking carries into account by decomposing these three inputs in base 1000 like for the input operands):
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I have finally embarked on my first machine learning MOOC / Specialization. I love Python, and this course uses Python as the language of choice. Also, the instructors assert that Python is widely used in industry, and is becoming the de facto language for data science in industry. They use IPython Notebook in their assignments and videos.
The specialization offered by the University of Washington consists of 5 courses and a capstone project spread across about 8 months (September through April). The specialization’s first iteration kicked off yesterday.
Key Learning Outcomes
– Identify potential applications of machine learning in practice.
– Describe the core differences in analyses enabled by regression, classification, and clustering.
– Select the appropriate machine learning task for a potential application.
– Apply regression, classification, clustering, retrieval, recommender systems, and deep learning.
– Represent your data as features to serve as input to machine learning models.
– Assess the model quality in terms of relevant error metrics for each task.
– Utilize a dataset to fit a model to analyze new data.
– Build an end-to-end application that uses machine learning at its core.
– Implement these techniques in Python.
Week-by-Week Week 1: Introductory welcome videos and the instructors’ views on the future of intelligent applications Week 2: Predicting House Prices (Regression) Week 3: Classification (Sentiment Analysis) Week 4: Clustering and Similarity: Retrieving Documents Week 5: Recommending Products Week 6: Deep Learning: Searching for Images
EDIT
It’s been 3 days since the course began, and here’s how the classmate demographic looks like:
I’m a newbie to the programming world. I first started programming in Python in May this year, a month after I started this blog, so I still haven’t learnt enough to contribute to economics as is the stated goal of this blog. But I know I’ll get there in a year or less.
This blog was also meant to document my learning. In May, I would have called myself Newb v0.0. Today, 3 months later, I’d like to call myself Newb v0.3 and the goal is to be at least Expert v1.0 by January 2016.
This is my solution to the first programming assignment of Tim Roughgarden’s course on Algorithms that was due 12:30 PM IST today. Here’s the question quoted as it is:
Programming Question-1
Download the text file here. (Right click and save link as) This file contains all of the 100,000 integers between 1 and 100,000 (inclusive) in some order, with no integer repeated.
Your task is to compute the number of inversions in the file given, where the ith row of the file indicates the ith entry of an array.
Because of the large size of this array, you should implement the fast divide-and-conquer algorithm covered in the video lectures. The numeric answer for the given input file should be typed in the space below.
So if your answer is 1198233847, then just type 1198233847 in the space provided without any space / commas / any other punctuation marks. You can make up to 5 attempts, and we’ll use the best one for grading.
(We do not require you to submit your code, so feel free to use any programming language you want — just type the final numeric answer in the following space.)
My Solution
I modified an earlier code I wrote for merge sort to arrive at the solution. It needed just a couple of modifications, and if you look carefully, it turns out that the number of inversions are unearthed each and every time we merge two sorted sub-arrays. So, intuitively, if the merge sort algorithm was O(nlog2n), it would take almost as many operations for counting inversions. In python, the code to sort and count inversions in an array of 10,000 integers took less than 3 seconds.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
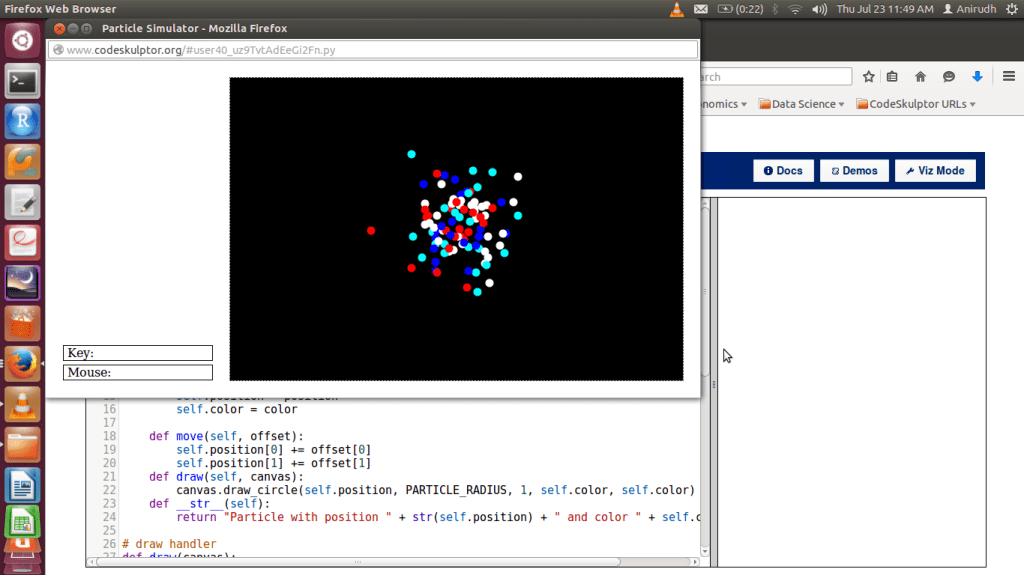
This class (Part 1 of a 2-part course on interactive programming using Python – and the first course of the Fundamentals of Computing Specialization offered by RICE Unviersity) was an excellent introduction to programming because of its focus on building interactive (and fun) applications with the lessons learned each week. Most introductory coding classes start with text based (boring?) programs, while all through this course you’re required to build a series of projects that get progressively complicated with every passing week. I’m not to be mistaken to be trashing conventional pedagogy, but then again, how many gifted coders do you know who learned to code after completing all the exercises, cover-to-cover of some programming textbook? The best way to learn to enjoy coding would be to build interactive stuff, and this course scores full points on that.
A short introduction to the class in a charmingly nerdy way
The mini-projects / assignments during the course are implemented on a cloud-based environment called CodeSkulptor (built by Scott Rixner, one of the instructors for this course). I found CodeSkulptor unique, in that it allows you to share your code (because it’s browser based) with just about anyone with an Internet connection and makes you work with a graphic user interface (GUI) module similar to Pygame, called Simplegui. It also had a debugging tool, called Viz Mode that helped visualize the process. It eases the task of debugging your code and you’ll realize how cool it is as you start using it more.
Since the course mini-projects were peer-reviewed, evaluating other people’s code also became a more straight-jacket affair, as everyone has their code on the same version of Python. This ensures that the focus is on learning to code, without wasting time on the logistics of programming environment (tuning differences in versions or IDEs). I especially enjoyed peer grading – for each mini project we completed, we had to evaluate and grade the work of 5 others. This was very rewarding – because I got the opportunity to fix bugs in others’ code (which makes you a better coder, I guess) and also got to see better implementations than the ones I had coded, further enriching the learning experience. Indeed, the benefits of peer grading and assessment have been well studied and documented.
Of all the assignments, the one I loved the most was implementing the classic arcade game Pong. You could try playing a version of the game I implemented here. It is a 2-player implementation, but you can play it as a single-player game, only if you imagine yourself to be answering this somewhat cheeky question! Which Pong character are you? Left or Right?
The principal reason behind my joining this course was the way it is structured and taught. We had to watch two sets of videos (part a and part b) and then complete one quiz for each set. The main task for each week was to complete a mini-project that was due along with the quizzes early Sunday morning, followed by assessment of peers’ mini-projects on the following Sunday-Wednesday. The instructors clearly put in A LOT OF WORK to make the lecture videos interesting, laced with humor, with just enough to get you going on your own with the week’s mini-project. That way you’d spend less time viewing the lecture videos, spending more time on actually getting the code for your mini-project to work. So in a way, one might say this course doesn’t follow standard pedagogy for an introductory programming course, but then, as Scott Rixner assures, “You’d know enough to be dangerous!”
– Rock Paper Scissors Lizard Spock: A simple implementation played with the computer. This project covers basics on statements, expressions and variables, functions, logic and conditionals [I’m a huge fan of The Big Bang Theory, so I was obviously eager to complete this game. Instead of a series of if-elif-else clauses, this implementation used modular logic, all of which is taught in a really fun way. A great way to start off the course].
– Guess the Number: Computer chooses a random number between 1 and 100 and you guess that number. It covered event-driven programming, local and global variables, buttons and input fields [This game although fun, might have been more interesting to code if the computer had to guess the number that the player chose, using bisection search].
– Stopwatch: This was the first project that used a graphic user interface, using some modular arithmetic to get the digits of the ticking seconds in place. A game was also built on it where the player had to stop the watch right at the start of a second to score points. This game tested your reaction-time. It covered static drawing, timers and interactive drawing.
– Pong: The last project of Part 1 and the most fun. Creating the game required only a minor step-up from learnings from previous weeks. It covered knowledge of lists, keyboard input, motion, positional/velocity control. Coding the ball physics where you put to use high-school physics knowledge of elasticity and collisions was very enjoyable. In my game, I set elasticity = 1 (for perfectly elastic collisions)
In an interview with the founders of this MOOC, who spent they say that they spent over 1000 hours building it (Part 1 and Part 2 combined, I guess). That’s an awful lot of effort and it all shows in how brilliantly the class is executed. The support system in the class is excellent. You’ll always find help available within minutes of posting your doubts and queries on the forums. I’ve seen Joe Warren (one of the main instructors of the course) replying to forum posts quite regularly. In addition, there was enough supplementary material in the form of pages on concepts and examples, practice exercises, and video content created by students from previous iterations of the class to better explain concepts and aspects of game-building, improving upon the lecture material.
Concepts and Examples
Practice Exercises
Student-created Videos Explaining Concepts
Overall, I had a great learning experience. I completed Part 1 with a 100 per cent score even though I had a minor hiccup while building the game Pong, which was the most satisfying of all the projects in Part 1. I would review Part 2 when I’m done with that in August this year. I’d easily recommend this course to anyone wishing to start off with Python. It is a great place to be introduced to Python, but it shouldn’t be your ONLY resource. I have been taking MIT’s 6.01x introductory Python course side-by-side. I shall review that course as soon as I’m through with it. That course is pedagogically more text-bookish, and indeed they do profess the use of their textbook to complement the course. I’m 4 weeks into that course and finding that enjoyable too – albeit in a different way. I still haven’t lost a point on any of the assignments or finger exercises there, and hope the trend continues:
PS: In one of the forum threads, Joe posted a list of resources that could be referred to in addition to the class.
http://pythonbooks.revolunet.com/ – about 50 books – Another good list of free python books that is kept up to date, and I believe are all free or open-source: (I won’t repeat all the books on the list here, just go check it out! Some are also on the list above, but not all)
Building a predictive data model for analyzing large textual data sets
Cleaning real-world data and perform complex regressions
Creating visualizations to communicate data analyses
Building a final data product in collaboration with SwiftKey, award-winning developer of leading keyboard apps for smartphones
I started with the R programming course where I found the programming assignments to be moderately difficult. They were good practice and also time-consuming for me since I haven’t yet gotten used to the R syntax, which is supposedly unintuitive. Anyway, I completed the course with distinction (90+ marks) scoring 95 on 100, losing 5 because I hadn’t familiarized myself with Git / GitHub. I did this course for a verified certificate, which cost me $29, and looks like this:
I won’t be paying for any of the remaining courses though, but still will get a certificate of accomplishment for each course I pass. I have alredy begun with Getting and Cleaning Data and Data Scientist’s Toolbox.
I checked today, and it seems Andrew Ng’s Machine Learning course has gone open to all and is self-paced. A lot of people have gone on to participate in Kaggle competitions with what they learnt in his course, so I’d like to experience it — even though it’s taught with Octave / MATLAB. My very short term goal is to start participating in these competitions ASAP.
I will be learning the basics of Git this week and along with that, about reading from MySQL, HDF5, the web and APIs. I intend to start reading Trevor Hastie’s highly recommended book, Introduction to Statistical Learning.
Meanwhile, I need to get started with Git and GitHub too, and I found a very useful blog by Kevin Markham and his short concise videos are great introductory material.
Incidentally, I was in a dilemma whether to start with Hastie’s material or Andrew Ng’s course first. This is what Kevin had to say
The only reason I have reservations against Andrew Ng’s course is that its instruction isn’t in R or Python. Also, CTO and co-founder of Kaggle, Ben Hamner mentions here how useful R and Python are vis-à-vis Matlab / Octave.


 single-digit multiplications in general (and exactly
single-digit multiplications in general (and exactly  when n is a power of 2). Although the familiar grade school algorithm for multiplying numbers is how we work through multiplication in our day-to-day lives, it’s slower (
when n is a power of 2). Although the familiar grade school algorithm for multiplying numbers is how we work through multiplication in our day-to-day lives, it’s slower ( ) in comparison, but only on a computer, of course!
) in comparison, but only on a computer, of course!


 and
and  be represented as
be represented as  -digit strings in some
-digit strings in some  . For any positive integer
. For any positive integer  less than
less than 
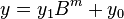 ,
,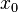 and
and 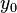 are less than
are less than  . The product is then
. The product is then
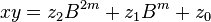



 can be computed in only three multiplications, at the cost of a few extra additions. With
can be computed in only three multiplications, at the cost of a few extra additions. With 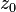 and
and 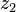 as before we can calculate
as before we can calculate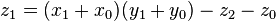
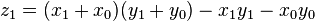
 , where
, where 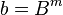 .
.