This post contains links to a bunch of code that I have written to complete Andrew Ng’s famous machine learning course which includes several interesting machine learning problems that needed to be solved using the Octave / Matlab programming language. I’m not sure I’d ever be programming in Octave after this course, but learning Octave just so that I could complete this course seemed worth the time and effort. I would usually work on the programming assignments on Sundays and spend several hours coding in Octave, telling myself that I would later replicate the exercises in Python.
If you’ve taken this course and found some of the assignments hard to complete, I think it might not hurt to go check online on how a particular function was implemented. If you end up copying the entire code, it’s probably your loss in the long run. But then John Maynard Keynes once said, ‘In the long run we are all dead‘. Yeah, and we wonder why people call Economics the dismal science!
Most people disregard Coursera’s feeble attempt at reigning in plagiarism by creating an Honor Code, precisely because this so-called code-of-conduct can be easily circumvented. I don’t mind posting solutions to a course’s programming assignments because GitHub is full to the brim with such content. Plus, it’s always good to read others’ code even if you implemented a function correctly. It helps understand the different ways of tackling a given programming problem.
My first brush with NumPy happened over writing a block of code to make a plot using pylab. ⇣
pylab is part of matplotlib (in matplotlib.pylab) and tries to give you a MatLab like environment. matplotlib has a number of dependencies, among them numpy which it imports under the common alias np. scipy is not a dependency of matplotlib.
I had a tuple (of lows and highs of temperature) of lengh 2 with 31 entries in each (the number of days in the month of July), parsed from this text file:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Given below, are 2 sets of code that do the same thing; one without NumPy and the other with NumPy. They output the following graph using PyLab:
Code without NumPy
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
diffTemps = [highTemps[i] - lowTemps[i] for i in range(len(lowTemps))]
Notice how straight forward it is with NumPy. At the core of the NumPy package, is the ndarray object. This encapsulates n-dimensional arrays of homogeneous data types, with many operations being performed in compiled code for performance. element-by-element operations are the “default mode” when an ndarray is involved, but the element-by-element operation is speedily executed by pre-compiled C code.
I’ve enrolled in Stanford Professor Tim Roughgarden’s Coursera MOOC on the design and analysis of algorithms, and while he covers the theory and intuition behind the algorithms in a surprising amount of detail, we’re left to implement them in a programming language of our choice.
And I’m ging to post Python code for all the algorithms covered during the course!
The Karatsuba Multiplication Algorithm
Karatsuba’s algorithm reduces the multiplication of two n-digit numbers to at most single-digit multiplications in general (and exactly when n is a power of 2). Although the familiar grade school algorithm for multiplying numbers is how we work through multiplication in our day-to-day lives, it’s slower () in comparison, but only on a computer, of course!
Here’s how the grade school algorithm looks: (The following slides have been taken from Tim Roughgarden’s notes. They serve as a good illustration. I hope he doesn’t mind my sharing them.)
…and this is how Karatsuba Multiplication works on the same problem:
A More General Treatment
Let and be represented as -digit strings in some base. For any positive integer less than , one can write the two given numbers as
,
where and are less than . The product is then
where
These formulae require four multiplications, and were known to Charles Babbage. Karatsuba observed that can be computed in only three multiplications, at the cost of a few extra additions. With and as before we can calculate
which holds since
A more efficient implementation of Karatsuba multiplication can be set as , where .
Example
To compute the product of 12345 and 6789, choose B = 10 and m = 3. Then we decompose the input operands using the resulting base (Bm = 1000), as:
12345 = 12 · 1000 + 345
6789 = 6 · 1000 + 789
Only three multiplications, which operate on smaller integers, are used to compute three partial results:
We get the result by just adding these three partial results, shifted accordingly (and then taking carries into account by decomposing these three inputs in base 1000 like for the input operands):
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I recently came across an interesting thread on Reddit on the origins of this cartoon. Basically, the cartoonist, ergo Python-speaking-Harry, got their code from this Stack Overflow forum for short, useful Python code snippets! Convenient, right?!
What’s funny is that the forum later got closed as it was deemed not constructive!
Click Image to Enlarge
The code is supposed to print a recursive count of lines of python source code from the current working directory, including an ignore list – so as to print total sloc. Don’t blame me though, if the code doesn’t work!
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Yet another exciting math problem that requires an algorithmic approach to arrive at a quick solution! There is a pen-paper approach to it too, but this post assumes we’re more interested in discussing the programming angle.
Working clockwise, and starting from the group of three with the numerically lowest external node (4,3,2 in this example), each solution can be described uniquely. For example, the above solution can be described by the set: 4,3,2; 6,2,1; 5,1,3.
It is possible to complete the ring with four different totals: 9, 10, 11, and 12. There are eight solutions in total.
Total Solution Set: 9 4,2,3; 5,3,1; 6,1,2 9 4,3,2; 6,2,1; 5,1,3 10 2,3,5; 4,5,1; 6,1,3 10 2,5,3; 6,3,1; 4,1,5 11 1,4,6; 3,6,2; 5,2,4 11 1,6,4; 5,4,2; 3,2,6 12 1,5,6; 2,6,4; 3,4,5 12 1,6,5; 3,5,4; 2,4,6
By concatenating each group it is possible to form 9-digit strings; the maximum string for a 3-gon ring is432621513.
Problem
Using the numbers 1 to 10, and depending on arrangements, it is possible to form 16-and 17-digit strings. What is the maximum 16-digit string for a “magic” 5-gon ring?
Algorithm
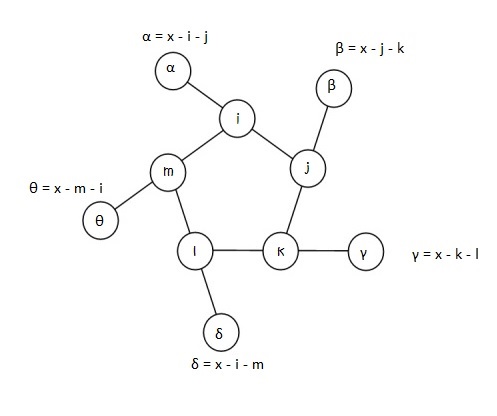
In attempting this problem, I choose to label the 5 inner nodes as i, j, k, l, and m. α, β, γ, δ, and θ being the corresponding outer nodes.
Let x be the sum total of each triplet line, i.e.,
x = α + i + j = β + j + k = γ + k + l = δ + l + m = θ + m + i
First Observation:
For the string to be 16-digits, 10 has to be in the outer ring, as each number in the inner ring is included in the string twice. Next, we fill the inner ring in an iterative manner.
Second Observation:
There 9 numbers to choose from for the inner ring — 1, 2, 3, 4, 5, 6, 7, 8 and 9.
5 have to be chosen. This can be done in 9C5 = 126 ways.
According to circular permutation, if there are n distinct numbers to be arranged in a circle, this can be done in (n-1)! ways, where (n-1)!= (n-1).(n-2).(n-3)…3.2.1. So 5 distinct numbers can be arranged in 4! permutations, i.e., in 24 ways around a circle, or pentagonal ring, to be more precise.
So in all, this problem can be solved in 126×24 =3024 iterations.
Third Observation:
For every possible permutation of an inner-ring arrangement, there can be one or more values of x(triplet line-sum) that serve as a possible contenders for a “magic”string whose triplets add up to the same number, x. To ensure this, we only need that the values of αthroughθ of the outer ring are distinct, different from the inner ring, with the greatest of these equal to 10.
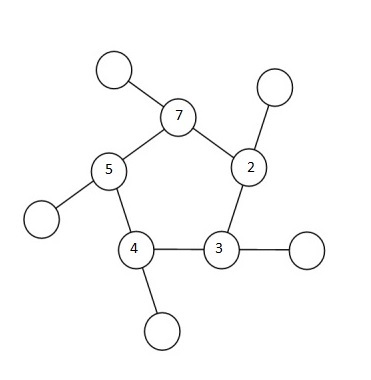
Depending on the relative positioning of the numbers in the inner ring, one can narrow the range of x-values one might have to check for each permutation. To zero-down on such a range, let’s look at an example. Shown in the figure below is a randomly chosen permutation of number in the inner ring – 7, 2, 3, 4 and 5, in that order.
So 10, 9, 8, 6 and 1 must fill the outer circle. It’s easy to notice that the 5, 7 pair is the greatest adjacent pair. So whatever x is, it has to be at least5 + 7 + 1 = 13 (1 being the smallest number of the outer ring). Likewise, 2, 3 is the smallest adjacent pair, so whatever x is, it can’t be any more than 2 + 3+ 10 = 15 (10 being the largest number of the outer ring). This leaves us with a narrow range of x-values to check – 13, 14 and 15.
Next, we arrange the 5 triplets in clock-wise direction starting with the triplet with the smallest number in the outer ring to form a candidate string. This exercise when done for each of the 3024permutations will shortlist a range of candidates, of which, the maximum is chosen.
That’s all there is to the problem!
Here’s the Python Code. It executes in about a tenth of a second!
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I came across this problem recently that required solving for the maximum-sum path in a triangle array.
To copy the above triangle array:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
As can be seen, there are 15 levels to this tree (including the top most node). Therefore, there are 214 possible routes to scan in order to check for the maximum sum using brute force. As there are only 214 (16384) routes, it is possible to solve this problem by trying every route. However, doing the same using brute force on a triangle array of 100 levels would take several billion years to solve using a computer that checks through say, 1012 routes per second. A greedy algorithm might per-chance work for the particular 4-level example problem stated above, but will not always work, and in most cases won’t. For instance, for the 100-level problem:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Solving such a problem would require a powerful approach – and surely enough, there is an algorithm that solves the 100-level problem in a fraction of a second. Here’s a brief sketch of the algorithm:
You have such triangle:
3
7 4
2 4 6
8 5 9 3
Let’s say you’re on the penultimate level 2 4 6 and you have to iterate over it.
From 2, you can go to either 8 or 5, so 8 is better (maximize you result by 3) so you calculate the first sum 8 + 2 = 10
From 4, you can go to either 5 or 9, so 9 is better (maximize you result by 4) so you calculate the second sum 9 + 4 = 13
From 6, you can go to either 9 or 3, so 9 is better again (maximize you result by 6) so you calculate the third sum 9 + 6 = 15
This is the end of first iteration and you got the line of sums 10 13 15.
Now you’ve got triangle of lower dimension:
3
7 4
10 13 15
Keep going this way…
3
20 19
…and you finally arrive at 23 as the answer.
The Code
Now for the Python code. I first store the 100-level triangle array in a text file, euler67.txt
I read the triangle array into Python and successively update the penultimate row and delete the last row according to the algorithm discussed above.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Many problems in Project Euler relate to working with primes. I use primesieve-python to help solve such problems. It consists of Python bindings for the primesieve C++ library. Generates primes orders of magnitude faster than any pure Python code. Features:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I started solving Project Euler problems this month. Check out the Project Euler tab of this blog for a list of the problems I’ve solved (with solutions) till date. Here’s a problem you might find interesting:
Here’s my solution using Python (I basically search through the entire matrix which is of O(n²) complexity):
I first copy the maxtrix into a text file euler11.txt so that it can be later read into Python
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I then execute the following code from the same working directory as euler11.txt
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I’m a newbie to the programming world. I first started programming in Python in May this year, a month after I started this blog, so I still haven’t learnt enough to contribute to economics as is the stated goal of this blog. But I know I’ll get there in a year or less.
This blog was also meant to document my learning. In May, I would have called myself Newb v0.0. Today, 3 months later, I’d like to call myself Newb v0.3 and the goal is to be at least Expert v1.0 by January 2016.
I have just begun working on a MOOC on algorithms offered by Stanford. Since this course gives us the liberty to choose a programming language, there isn’t any code discussed in those lectures. I plan to convert any algorithm discussed in those lectures into Python code. Since Merge Sort was the first algorithm discussed, I’m starting with that.
— Recursively sort the first half of the input array. — Recursively sort the second half of the input array. — Merge two sorted sub-lists into one list.
C = output [length = n]
A = 1st sorted array [n/2]
B = 2nd sorted array [n/2]
i = 0 or 1 (depending on the programming language)
j = 0 or 1 (depending on the programming language)
for k = 1 to n
if A(i) < B(j) C(k) = A(i) i = i + 1
else if A(i) > B(j) C(k) = B(j) j = j + 1
Note: the pseudocode for the merge operation ignores the end cases.
Visualizing the algorithm can be done in 2 stages — first, the recursive splitting of the arrays, 2 each 2 at a time, and second, the merge operation.
Here’s the Python code to merge sort an array.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
We can divide a list in half log2n times where n is the length of the list. The second process is the merge. Each item in the list will eventually be processed and placed on the sorted list. So the merge operation which results in a list of size n requiresn operations. The result of this analysis is that log2n splits, each of which costs n for a total of nlog2n operations.

 single-digit multiplications in general (and exactly
single-digit multiplications in general (and exactly  when n is a power of 2). Although the familiar grade school algorithm for multiplying numbers is how we work through multiplication in our day-to-day lives, it’s slower (
when n is a power of 2). Although the familiar grade school algorithm for multiplying numbers is how we work through multiplication in our day-to-day lives, it’s slower ( ) in comparison, but only on a computer, of course!
) in comparison, but only on a computer, of course!


 and
and  be represented as
be represented as  -digit strings in some
-digit strings in some  . For any positive integer
. For any positive integer  less than
less than 
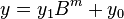 ,
, and
and 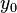 are less than
are less than  . The product is then
. The product is then
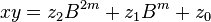



 can be computed in only three multiplications, at the cost of a few extra additions. With
can be computed in only three multiplications, at the cost of a few extra additions. With 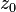 and
and 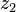 as before we can calculate
as before we can calculate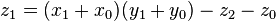
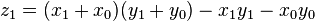
 , where
, where 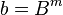 .
.