There are 2 popular ways of representing an undirected graph.
Adjacency List
Each list describes the set of neighbors of a vertex in the graph.

Adjacency Matrix
The elements of the matrix indicate whether pairs of vertices are adjacent or not in the graph.

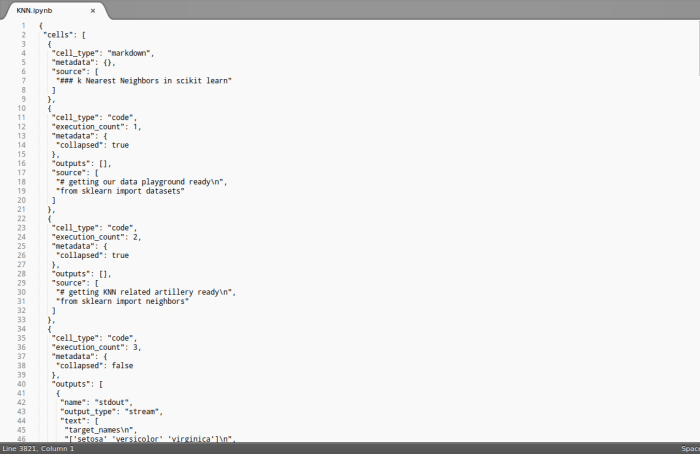
Here’s an implementation of the above in Python:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| class Vertex: | |
| def __init__(self, vertex): | |
| self.name = vertex | |
| self.neighbors = [] | |
| def add_neighbor(self, neighbor): | |
| if isinstance(neighbor, Vertex): | |
| if neighbor.name not in self.neighbors: | |
| self.neighbors.append(neighbor.name) | |
| neighbor.neighbors.append(self.name) | |
| self.neighbors = sorted(self.neighbors) | |
| neighbor.neighbors = sorted(neighbor.neighbors) | |
| else: | |
| return False | |
| def add_neighbors(self, neighbors): | |
| for neighbor in neighbors: | |
| if isinstance(neighbor, Vertex): | |
| if neighbor.name not in self.neighbors: | |
| self.neighbors.append(neighbor.name) | |
| neighbor.neighbors.append(self.name) | |
| self.neighbors = sorted(self.neighbors) | |
| neighbor.neighbors = sorted(neighbor.neighbors) | |
| else: | |
| return False | |
| def __repr__(self): | |
| return str(self.neighbors) | |
| class Graph: | |
| def __init__(self): | |
| self.vertices = {} | |
| def add_vertex(self, vertex): | |
| if isinstance(vertex, Vertex): | |
| self.vertices[vertex.name] = vertex.neighbors | |
| def add_vertices(self, vertices): | |
| for vertex in vertices: | |
| if isinstance(vertex, Vertex): | |
| self.vertices[vertex.name] = vertex.neighbors | |
| def add_edge(self, vertex_from, vertex_to): | |
| if isinstance(vertex_from, Vertex) and isinstance(vertex_to, Vertex): | |
| vertex_from.add_neighbor(vertex_to) | |
| if isinstance(vertex_from, Vertex) and isinstance(vertex_to, Vertex): | |
| self.vertices[vertex_from.name] = vertex_from.neighbors | |
| self.vertices[vertex_to.name] = vertex_to.neighbors | |
| def add_edges(self, edges): | |
| for edge in edges: | |
| self.add_edge(edge[0],edge[1]) | |
| def adjacencyList(self): | |
| if len(self.vertices) >= 1: | |
| return [str(key) + ":" + str(self.vertices[key]) for key in self.vertices.keys()] | |
| else: | |
| return dict() | |
| def adjacencyMatrix(self): | |
| if len(self.vertices) >= 1: | |
| self.vertex_names = sorted(g.vertices.keys()) | |
| self.vertex_indices = dict(zip(self.vertex_names, range(len(self.vertex_names)))) | |
| import numpy as np | |
| self.adjacency_matrix = np.zeros(shape=(len(self.vertices),len(self.vertices))) | |
| for i in range(len(self.vertex_names)): | |
| for j in range(i, len(self.vertices)): | |
| for el in g.vertices[self.vertex_names[i]]: | |
| j = g.vertex_indices[el] | |
| self.adjacency_matrix[i,j] = 1 | |
| return self.adjacency_matrix | |
| else: | |
| return dict() | |
| def graph(g): | |
| """ Function to print a graph as adjacency list and adjacency matrix. """ | |
| return str(g.adjacencyList()) + '\n' + '\n' + str(g.adjacencyMatrix()) | |
| ################################################################################### | |
| a = Vertex('A') | |
| b = Vertex('B') | |
| c = Vertex('C') | |
| d = Vertex('D') | |
| e = Vertex('E') | |
| a.add_neighbors([b,c,e]) | |
| b.add_neighbors([a,c]) | |
| c.add_neighbors([b,d,a,e]) | |
| d.add_neighbor(c) | |
| e.add_neighbors([a,c]) | |
| g = Graph() | |
| print(graph(g)) | |
| print() | |
| g.add_vertices([a,b,c,d,e]) | |
| g.add_edge(b,d) | |
| print(graph(g)) |
Output:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| {} | |
| {} | |
| ["A:['B', 'C', 'E']", "C:['A', 'B', 'D', 'E']", "B:['A', 'C', 'D']", "E:['A', 'C']", "D:['B', 'C']"] | |
| [[ 0. 1. 1. 0. 1.] | |
| [ 1. 0. 1. 1. 0.] | |
| [ 1. 1. 0. 1. 1.] | |
| [ 0. 1. 1. 0. 0.] | |
| [ 1. 0. 1. 0. 0.]] |