Very often we find ourselves caught up with really mundane tasks involving voluminous excel data — in business and yes, even in research! The story keeps repeating everywhere. I’ll talk about how to automate some mechanical and brain-dead spreadsheet operations using R. This post will cover the basics of reading and writing operations on Excel data. There are 2 packages worth installing, that I’ve taken a liking to for this purpose. xlsx and XLConnect.
install.packages("xlsx","XLConnect")
Let’s say you have huge volumes of spreadsheet data, of a survey conducted in a city several times during the year (like every month or so). What if you were interested in only some of the details from that survey, and you wanted to extract those details for each time the survey was conducted that year, and summarize the whole thing in yet another spreadsheet. You don’t want to be repeatedly copying and pasting and wasting several man-hours doing so, especially if you had hundreds of surveys to scavenge from. Instead, a simple R script could complete the same task in minutes.
I’ll talk about an example scenario and walk you through the R code. I had data coming from a survey conducted every month of the year for the district of Agra, India — home to the Taj Mahal. Since they were the same survey conducted every month, the excel files were identical in format. Each file contained different data, but of same parameters being tested each month – so data in specific cells, say, E11:V11 were instances of the same metric common to each file. I wanted to stack data from these particular cells from each file onto a fresh excel workbook. I could have copy-pasted the whole thing and done the job manually, but I wasn’t just looking at data from one district, viz., Agra, but hundreds of other districts. This was obviously a task that badly needed automating.
So, for Agra, I had 12 spreadsheets corresponding to surveys for each month of the year. The R file (Agra) that you can see along with the excel files, is the script for creating the final spreadsheet that accomplished the earlier-mentioned objective.
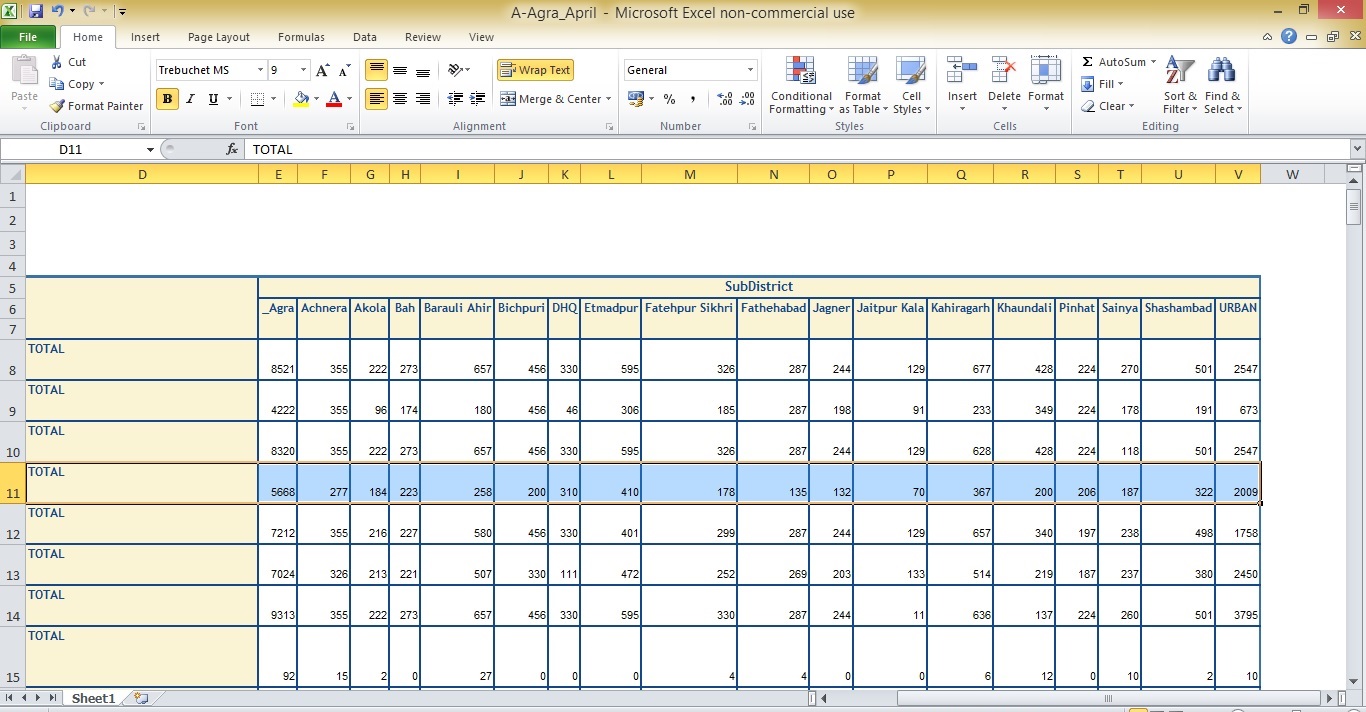
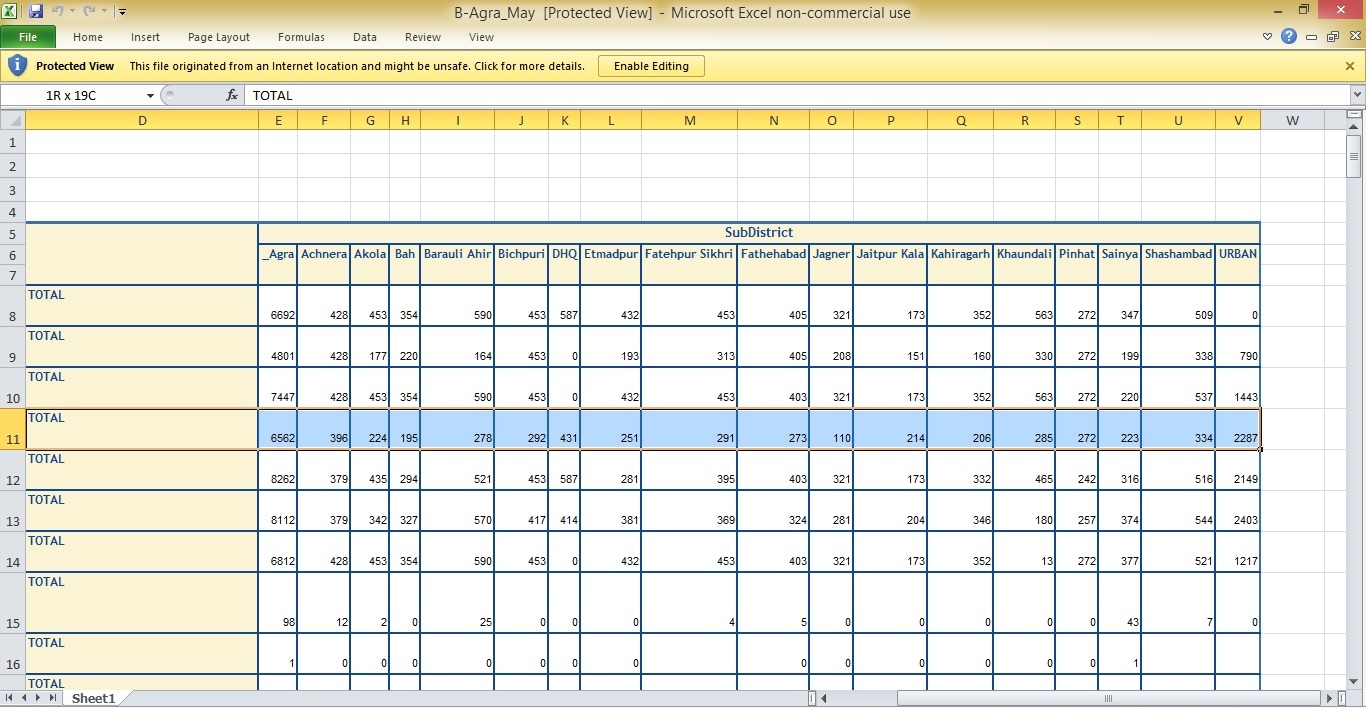
I wanted data taken from the cells E11:V11 from each of the above spreadsheets. For example, here’s how it looks for the April and May spreadsheets (highlighted portion)
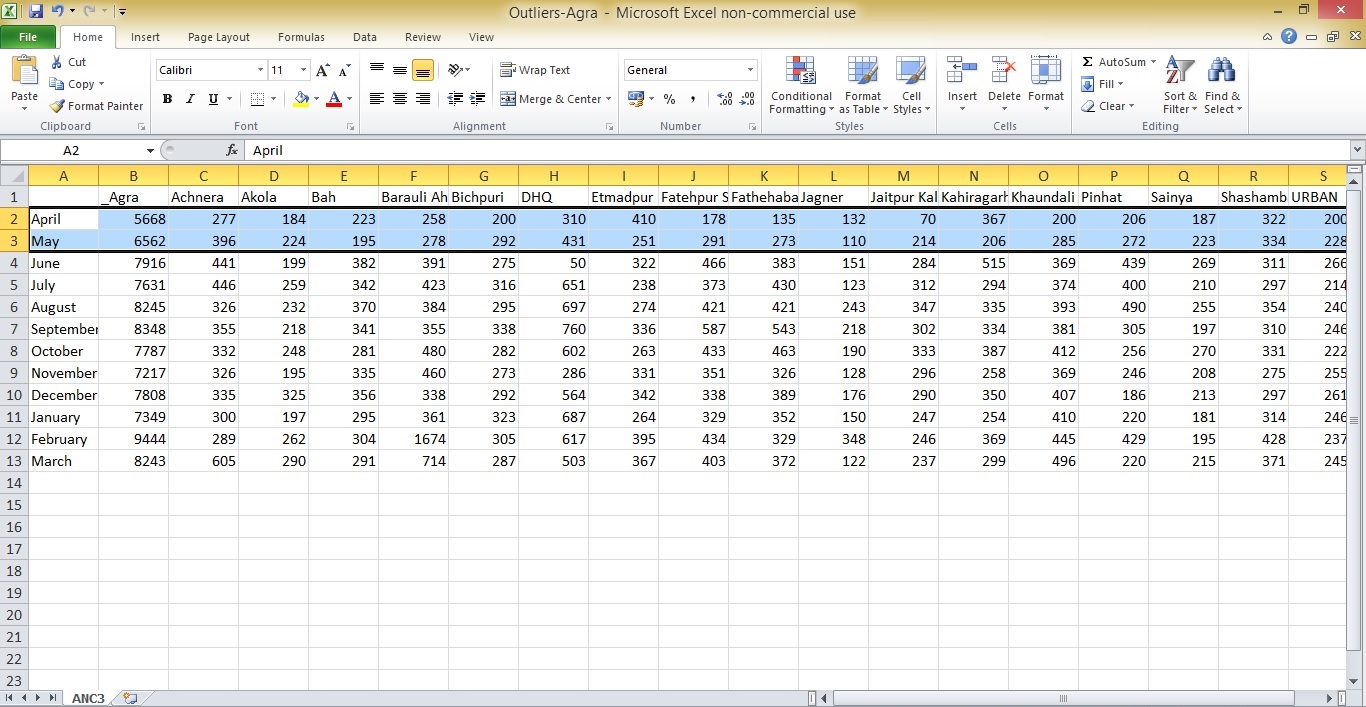
I had to write R code to get the data from each of the spreadsheets to be neatly stacked in a fresh workbook named Outliers-Agra, and give appropriate row names, column names, and worksheet name, as in the screenshot below.
How was this done using R?
First, the necessary libraries had to be loaded into R, the ones talked about at the start of this post.
library("xlsx") library("XLConnect")
Next, I had to change the working directory to where the survey data was kept, in this case, a folder aptly named Agra. The files in the directory were stored in a vector named files. Since the main R-file where I was writing the script Agra.R, was part of that directory, it also was part of the vector files. The vector files was created to later read the spreadsheets iteratively using a for-loop, so Agra.R had to be deleted from it. This was done using the which() function to locate the position of the R-file, craftily using subsetting rules to remove it from the vector.
setwd("C:/Anirudh/Coding/R/Agra") ## CHANGE WORKING DIRECTORY as required files <- list.files() ## vector containing the file names in that directory files <- files[-which(files == "Agra.R")] ## Removes R-file (in this case, Agra.R) from the vector of files
An empty matrix, temp, was created to be exactly the size of the data to be read from all the excel files in the directory. The data from each file was then iteratively stored to fill temp. The read.xlsx() function is a function from the xlsx library. The arguments are mostly self-explanatory. files[i] subsets the ith instance in files. header is set FALSE to indicate that the top row of the excel file did not consist of variables.
temp <- matrix(nrow = length(files), ncol = 18) ## matrix, 18 columns as in 5:22, rows = no.of xls files for(i in seq_along(files[1:length(files)])) { dat <- read.xlsx(files[i], sheetIndex = 1, rowIndex = 11, colIndex = 5:22, header = FALSE) mat <- as.matrix(dat) ## reading data from 11th row of xlsx file into a matrix of row size 1 temp[i,] <- mat ## storing data from above matrix into matrix temp }
The contents of temp (a matrix object) were then stored in a data frame object before being written to a fresh excel file (this is necessary). For writing operations in excel, I used functions from the XLConnect library. The workbook had to be loaded using loadWorkbook() with the create argument set to TRUE to indicate that a fresh excel file was being created. If I had to write to an already existing file, the argument would have been set FALSE . I created a worksheet and named it ANC3 (that had got something to do with the data). startRow and startCol are set to the location where we want the data to begin from.
df <- as.data.frame(temp) ## storing contents of temp matrix as data frame
wb <- loadWorkbook("C:/Anirudh/Coding/R/Agra/Outliers-Agra.xlsx", create = TRUE) # new workbook
createSheet(wb, name = "ANC3") ## create worksheet / tab with name "ANC3"
writeWorksheet(wb, df, sheet = "ANC3", startRow = 2, startCol = 2, header = FALSE)
Next, the data in the new excel file, Outliers-Agra.xlsx was given appropriate column names (colnames) and row names (months).
colnames <- read.xlsx(files[i],sheetIndex = 1, rowIndex = 6, colIndex = 5:22, header = FALSE) colnames <- as.data.frame(as.matrix(colnames)) months <- as.data.frame(matrix(c("April", "May", "June", "July", "August", "September","October", "November","December", "January", "February", "March"))) writeWorksheet(wb, colnames, sheet = "ANC3", startRow = 1, startCol = 2, header = FALSE) writeWorksheet(wb, months, sheet = "ANC3", startRow = 2, startCol = 1, header = FALSE)
Lastly, the workbook needed to be saved.
saveWorkbook(wb)
After executing the R script, the new workbook Outliers-Agra is added to the parent directory.
So this is how some basic Excel work can be managed using R. Since these were only 12 files, writing all this code to perform simple copy and paste functions might seem like an awful lot to go through. But the data in this example was for one Indian district (Agra) — and if you had to do the same thing thousands of times covering hundreds of districts (directories), you’d thank this gem of free software known as R, for what it can accomplish.
Featured Image: https://xkcd.com/1445/
