I recently got myself to start using Python on Windows, whereas till very recently I had been working on Python only from Ubuntu.
I am sure I am late in realizing this, but installing Tensorflow was just so easy!
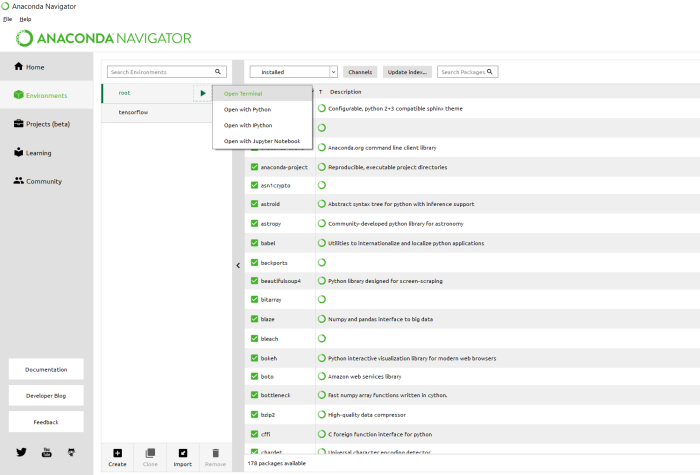
If you’ve tried installing Tensorflow for Windows when it was first introduced, and gave up back then – try again. The method I’d recommend would be using Anaconda Navigator from where you first open a terminal (figure below). You may notice that I already have a tensorflow environment set up, since I am writing this post after installation.
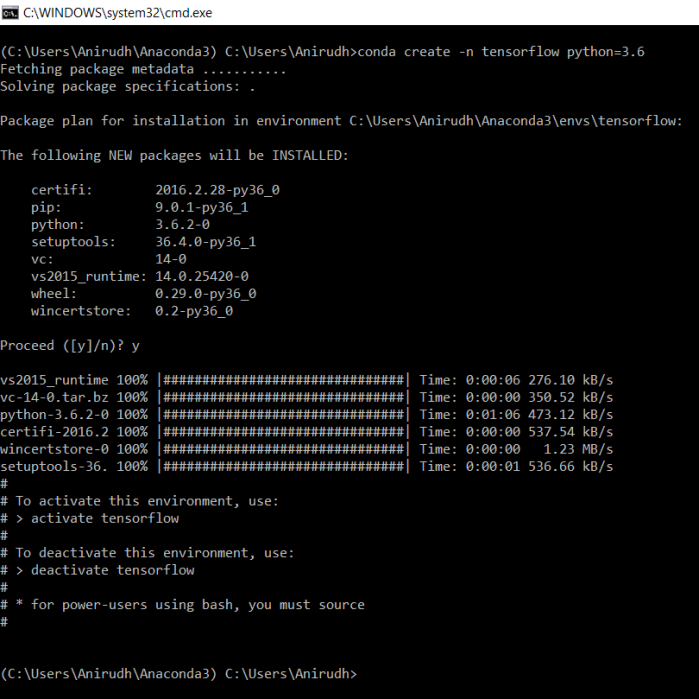
Once you have terminal open, create a conda environment named tensorflow by invoking the following command, with your python version:
C:> conda create -n tensorflow python=3.6
That’s all! You should now have tensorflow ready to use.
For more details, you could always go here. Otherwise, the screenshot below gives a sense of what it takes.
Let’s say you have data containing a categorical variable with 50 levels. When you divide the data into train and test sets, chances are you don’t have all 50 levels featuring in your training set.
This often happens when you divide the data set into train and test sets according to the distribution of the outcome variable. In doing so, chances are that our explanatory categorical variable might not be distributed exactly the same way in train and test sets – so much so that certain levels of this categorical variable are missing from the training set. The more levels there are to a categorical variable, it gets difficult for that variable to be similarly represented upon splitting the data.
Take for instance this example data set (train.csv + test.csv) which contains a categorical variable var_b that takes 349 unique levels. Our train data has 334 of these levels – on which the model is built – and hence 15 levels are excluded from our trained model. If you try making predictions on the test set with this model in R, it throws an error: factor var_b has new levels 16060, 17300, 17980, 19060, 21420, 21820,
25220, 29340, 30300, 33260, 34100, 38340, 39660, 44300, 45460
If you’ve used R to model generalized linear class of models such as linear, logit or probit models, then chances are you’ve come across this problem – especially when you’re validating your trained model on test data.
The workaround to this problem is in the form of a function, remove_missing_levels that I found here written by pat-s. You need magrittr library installed and it can only work on lm, glm and glmmPQL objects.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Once you’ve sourced the above function in R, you can seamlessly proceed with using your trained model to make predictions on the test set. The code below demonstrates this for the data set shared above. You can find these codes in one of my github repos and try it out yourself.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I recently bought a new laptop and began installing essential software all over again, including R of course! And I wanted all the libraries that I had installed in my previous laptop. Instead of installing libraries one by one all over again, I did the following:
Step 1: Save a list of packages installed in your old computing device (from your old device).
This saves information on installed packages in a csv file named installed_previously.csv. Now copy or e-mail this file to your new device and access it from your working directory in R.
Step 2: Create a list of libraries from your old list that were not already installed when you freshly download R (from your new device).
We now have a list of libraries that were installed in your previous computer in addition to the R packages already installed when you download R. So you now go ahead and install these libraries.
Step 3: Download this list of libraries.
install.packages(toInstall)
That’s it. Save yourself the trouble installing packages one-by-one all over again.
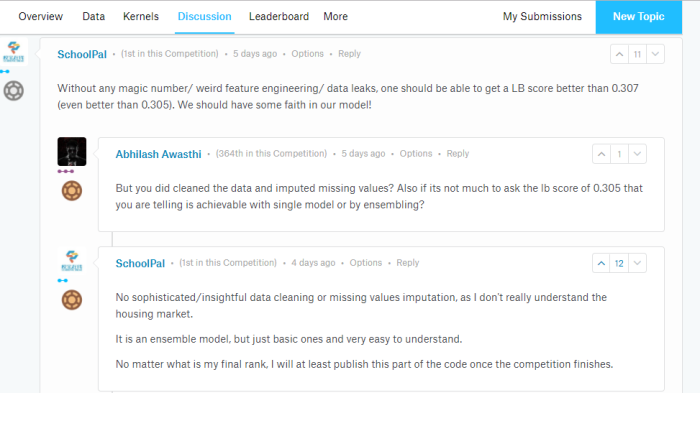
I’ve been stuck for about a week at the 52nd percentile among 3400+ Kagglers taking part in the competition. I’ve been told that Kaggle Kernels and discussion boards are helpful when you’re stuck or if you need to learn some practical data science that can’t be gleaned from books or tutorials.
One such discussion thread looks like this:
This person going by the pseudonym Schoolpal is currently killing it on the leaderboard and I’m eagerly looking forward to this person’s code once the competition ends in less than 24 hours. If you’re interested too, follow this discussion here.
Cheers!
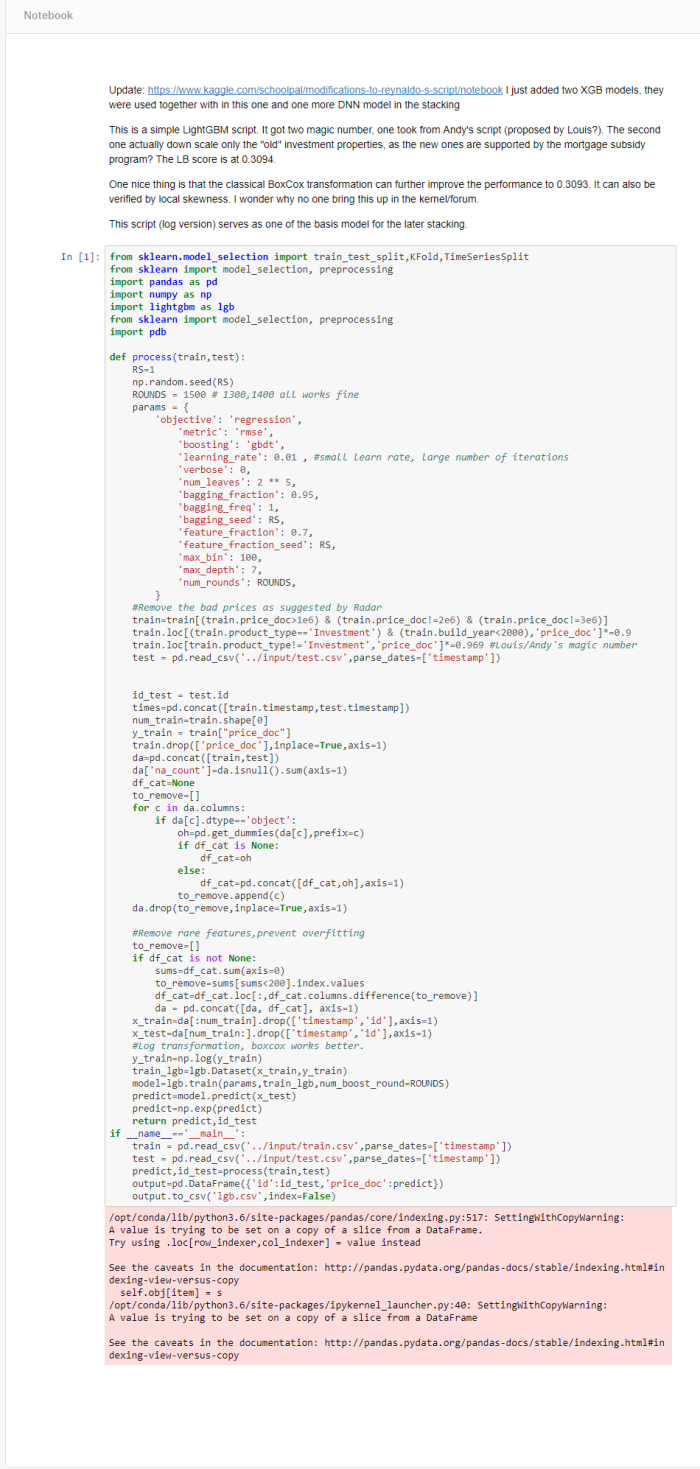
Update:
This Schoolpal, as mentioned earlier, finally came in second and shared their approach here.