…then no worries, there is a quick fix. I’ve been deliberately lousy with the presentation, so sorry about that. Chances are that no one’s going to end up reading this anyway. I saw this problem being discussed on a Dato forum, so I decided to blog about the fix.
EDIT: Note that this problem is in GraphLab Create v1.6 only. They came up with v1.6.1 a few days after the problem was escalated on their forum, so a good option would be to upgrade GraphLab Create.
The problem you face should looks something like this (click images below to enlarge):
To solve the problem:
Locate sframe.py from your home directory by searching for it from your desktop environment (applies to Windows users too). I found it in the following path on my computer:
I have finally embarked on my first machine learning MOOC / Specialization. I love Python, and this course uses Python as the language of choice. Also, the instructors assert that Python is widely used in industry, and is becoming the de facto language for data science in industry. They use IPython Notebook in their assignments and videos.
The specialization offered by the University of Washington consists of 5 courses and a capstone project spread across about 8 months (September through April). The specialization’s first iteration kicked off yesterday.
Key Learning Outcomes
– Identify potential applications of machine learning in practice.
– Describe the core differences in analyses enabled by regression, classification, and clustering.
– Select the appropriate machine learning task for a potential application.
– Apply regression, classification, clustering, retrieval, recommender systems, and deep learning.
– Represent your data as features to serve as input to machine learning models.
– Assess the model quality in terms of relevant error metrics for each task.
– Utilize a dataset to fit a model to analyze new data.
– Build an end-to-end application that uses machine learning at its core.
– Implement these techniques in Python.
Week-by-Week Week 1: Introductory welcome videos and the instructors’ views on the future of intelligent applications Week 2: Predicting House Prices (Regression) Week 3: Classification (Sentiment Analysis) Week 4: Clustering and Similarity: Retrieving Documents Week 5: Recommending Products Week 6: Deep Learning: Searching for Images
EDIT
It’s been 3 days since the course began, and here’s how the classmate demographic looks like:
Yet another exciting math problem that requires an algorithmic approach to arrive at a quick solution! There is a pen-paper approach to it too, but this post assumes we’re more interested in discussing the programming angle.
Working clockwise, and starting from the group of three with the numerically lowest external node (4,3,2 in this example), each solution can be described uniquely. For example, the above solution can be described by the set: 4,3,2; 6,2,1; 5,1,3.
It is possible to complete the ring with four different totals: 9, 10, 11, and 12. There are eight solutions in total.
Total Solution Set: 9 4,2,3; 5,3,1; 6,1,2 9 4,3,2; 6,2,1; 5,1,3 10 2,3,5; 4,5,1; 6,1,3 10 2,5,3; 6,3,1; 4,1,5 11 1,4,6; 3,6,2; 5,2,4 11 1,6,4; 5,4,2; 3,2,6 12 1,5,6; 2,6,4; 3,4,5 12 1,6,5; 3,5,4; 2,4,6
By concatenating each group it is possible to form 9-digit strings; the maximum string for a 3-gon ring is432621513.
Problem
Using the numbers 1 to 10, and depending on arrangements, it is possible to form 16-and 17-digit strings. What is the maximum 16-digit string for a “magic” 5-gon ring?
Algorithm
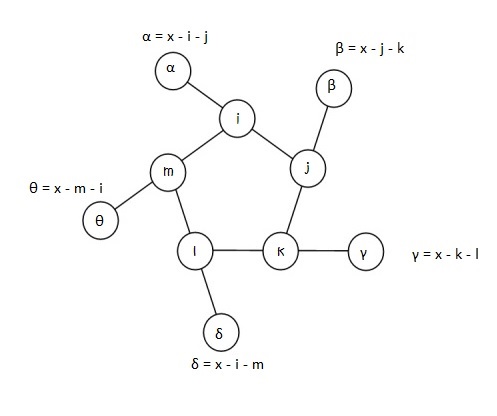
In attempting this problem, I choose to label the 5 inner nodes as i, j, k, l, and m. α, β, γ, δ, and θ being the corresponding outer nodes.
Let x be the sum total of each triplet line, i.e.,
x = α + i + j = β + j + k = γ + k + l = δ + l + m = θ + m + i
First Observation:
For the string to be 16-digits, 10 has to be in the outer ring, as each number in the inner ring is included in the string twice. Next, we fill the inner ring in an iterative manner.
Second Observation:
There 9 numbers to choose from for the inner ring — 1, 2, 3, 4, 5, 6, 7, 8 and 9.
5 have to be chosen. This can be done in 9C5 = 126 ways.
According to circular permutation, if there are n distinct numbers to be arranged in a circle, this can be done in (n-1)! ways, where (n-1)!= (n-1).(n-2).(n-3)…3.2.1. So 5 distinct numbers can be arranged in 4! permutations, i.e., in 24 ways around a circle, or pentagonal ring, to be more precise.
So in all, this problem can be solved in 126×24 =3024 iterations.
Third Observation:
For every possible permutation of an inner-ring arrangement, there can be one or more values of x(triplet line-sum) that serve as a possible contenders for a “magic”string whose triplets add up to the same number, x. To ensure this, we only need that the values of αthroughθ of the outer ring are distinct, different from the inner ring, with the greatest of these equal to 10.
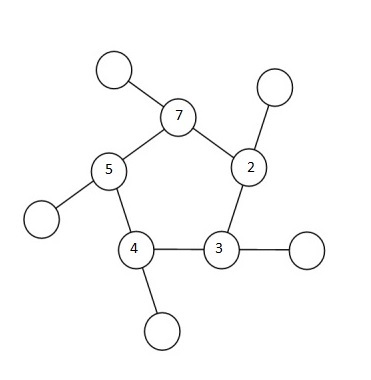
Depending on the relative positioning of the numbers in the inner ring, one can narrow the range of x-values one might have to check for each permutation. To zero-down on such a range, let’s look at an example. Shown in the figure below is a randomly chosen permutation of number in the inner ring – 7, 2, 3, 4 and 5, in that order.
So 10, 9, 8, 6 and 1 must fill the outer circle. It’s easy to notice that the 5, 7 pair is the greatest adjacent pair. So whatever x is, it has to be at least5 + 7 + 1 = 13 (1 being the smallest number of the outer ring). Likewise, 2, 3 is the smallest adjacent pair, so whatever x is, it can’t be any more than 2 + 3+ 10 = 15 (10 being the largest number of the outer ring). This leaves us with a narrow range of x-values to check – 13, 14 and 15.
Next, we arrange the 5 triplets in clock-wise direction starting with the triplet with the smallest number in the outer ring to form a candidate string. This exercise when done for each of the 3024permutations will shortlist a range of candidates, of which, the maximum is chosen.
That’s all there is to the problem!
Here’s the Python Code. It executes in about a tenth of a second!
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I came across this problem recently that required solving for the maximum-sum path in a triangle array.
To copy the above triangle array:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
As can be seen, there are 15 levels to this tree (including the top most node). Therefore, there are 214 possible routes to scan in order to check for the maximum sum using brute force. As there are only 214 (16384) routes, it is possible to solve this problem by trying every route. However, doing the same using brute force on a triangle array of 100 levels would take several billion years to solve using a computer that checks through say, 1012 routes per second. A greedy algorithm might per-chance work for the particular 4-level example problem stated above, but will not always work, and in most cases won’t. For instance, for the 100-level problem:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Solving such a problem would require a powerful approach – and surely enough, there is an algorithm that solves the 100-level problem in a fraction of a second. Here’s a brief sketch of the algorithm:
You have such triangle:
3
7 4
2 4 6
8 5 9 3
Let’s say you’re on the penultimate level 2 4 6 and you have to iterate over it.
From 2, you can go to either 8 or 5, so 8 is better (maximize you result by 3) so you calculate the first sum 8 + 2 = 10
From 4, you can go to either 5 or 9, so 9 is better (maximize you result by 4) so you calculate the second sum 9 + 4 = 13
From 6, you can go to either 9 or 3, so 9 is better again (maximize you result by 6) so you calculate the third sum 9 + 6 = 15
This is the end of first iteration and you got the line of sums 10 13 15.
Now you’ve got triangle of lower dimension:
3
7 4
10 13 15
Keep going this way…
3
20 19
…and you finally arrive at 23 as the answer.
The Code
Now for the Python code. I first store the 100-level triangle array in a text file, euler67.txt
I read the triangle array into Python and successively update the penultimate row and delete the last row according to the algorithm discussed above.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Like many of my previous posts, this post too has something to do with a Project Euler problem. Here’s a sketch of the Colatz Conjecture.
The following iterative sequence is defined for the set of positive integers:
n → n/2 (n is even) n → 3n + 1 (n is odd)
Using the rule above and starting with 13, we generate the following sequence:
13 → 40 → 20 → 10 → 5 → 16 → 8 → 4 → 2 → 1
So basically, it’s just this. Take any natural number n. If n is even, divide it by 2 to get n / 2. If n is odd, multiply it by 3 and add 1 to obtain 3n + 1. Repeat the process indefinitely. The conjecture is that no matter what number you start with, you will always eventually reach 1. The property has aptly been called oneness! But perhaps oneness has its pitfalls too…
If the conjecture is false, it can only be because there is some starting number which gives rise to a sequence that does not contain 1. Such a sequence might enter a repeating cycle that excludes 1, or increase without bound. No such sequence has been found.
Question
It can be seen that the sequence: 13 → 40 → 20 → 10 → 5 → 16 → 8 → 4 → 2 → 1
contains 10 terms. Although it has not been proved yet (Collatz Problem), it is thought that all starting numbers finish at 1. Which starting number, under one million, produces the longest chain?
NOTE: Once the chain starts the terms are allowed to go above one million.
HUGE HINT:
Histogram of stopping times for the numbers 1 to 100 million. Stopping time is on the x axis, frequency on the y axis.
Approach 1 (A naïve, but straigh forward method)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I couldn’t help appreciate the elegance of the second algorithm. It’ll be well worth perusing if you don’t get it at one go. [Hint: It keeps track of the number of terms of a particular sequence as values assigned to keys of a Python dictionary]
This isn’t much of a problem really, but since I’m posting solutions to all the Project Euler problems I solve, I’ve been OCD’d into posting this one too. Besides, it illustrates the simplifying power of Python as a language?
I first copy the problem matrix to a .txt file, in this case, euler13.txt
The solution is cake really, and I don’t care whether this was worth posting on my blog or not coz I wasted my time solving this problem anyway, and it shouldn’t have been for nothing!
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
All ∑n numbers are Triangle Numbers. They’re called so, because they can be represented in the form of a triangular grid of points where the first row contains a single element and each subsequent row contains one more element than the previous one.
Problem 12 of Project Euler asks for the first triangle number with more than 500 divisors.
These are the factors of the first seven triangle numbers:
First Step: Find the smallest number with 500 divisors. Seems like a good starting point to begin our search. Second Step: Starting at the number found in the previous step, search for the next triangle number. Check to see whether this number has 500+ divisors. If yes, this is the number we were looking for, else… Third Step: Check n for which ∑n = triangle number found in the previous step Fourth Step: Add (n+1) to the last triangle number found, to find the next triangle number. Check whether this number has 500+ divisors. If yes, this number is the answer. If not, repeat Fourth Step till the process terminates.
Now for the details:
The First Step isn’t exactly a piece of cake, but necessary to reduce computation time. I solved this with a bit of mental math. The main tool for the feat is the prime number decomposition theorem:
Every integer N is the product of powers of prime numbers
N = pαqβ· … · rγ
Where p, q, …, r are prime, while α, β, …, γ are positive integers. Such representation is unique up to the order of the prime factors.
If N is a power of a prime, N = pα, then it has α + 1 factors: 1, p, …, pα-1, pα
The total number of factors of N equals (α + 1)(β + 1) … (γ + 1)
500 = 2 x 2 x 5 x 5 x 5
So, the number in question should be of the form abq4r4s4 where a, b, q, r, s are primes that minimize abq4r4s4. This is satisfied by 7x11x24x34x54= 62370000. This marks the end of the First Step which is where we start our search for our magic number.
The next 3 steps would need helper functions defined as below:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
As can be seen from the above code, the algorithm to calculate divisors of an integer is as follows: 1. Start by inputting a number n 2. Let an int variable limit=√n 3. Run a loop from i = 1 to i = limit 3.1 if n is divisible by i 3.1.1 Add i to the list of divisors 3.1.2 if i and n/i are unequal, add n/i to the list too. 4. End
Finally, executing the 4 steps mentioned earlier can be done like so (the code took less than 2s to arrive at the answer):
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Many problems in Project Euler relate to working with primes. I use primesieve-python to help solve such problems. It consists of Python bindings for the primesieve C++ library. Generates primes orders of magnitude faster than any pure Python code. Features:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I started solving Project Euler problems this month. Check out the Project Euler tab of this blog for a list of the problems I’ve solved (with solutions) till date. Here’s a problem you might find interesting:
Here’s my solution using Python (I basically search through the entire matrix which is of O(n²) complexity):
I first copy the maxtrix into a text file euler11.txt so that it can be later read into Python
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I then execute the following code from the same working directory as euler11.txt
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I enrolled in Introduction to Computer Science and Programming Using Python with the primary objective of learning to code using Python. This course, as the name suggests, is more than just about Python. It uses Python as a tool to teach computational thinking and serves as an introduction to computer science. The fact that it is a course offered by MIT, makes it special.
As a matter of fact, this course is aimed at students with little or no prior programming experience who feel the need to understand computational approaches to problem solving. Eric Grimson is an excellent teacher (also Chancellor of MIT) and he delves into the subject matter to a surprising amount of detail.
The video lectures are based on select chapters from an excellent book by John Guttag. While the book isn’t mandatory for the course (the video lectures do a great job of explaining the material on their own), I benefited greatly from reading the textbook. There are a couple of instances where the code isn’t presented properly in the slides (typos or indentation gone wrong when pasting code to the slides), but the correct code / study material can be found in the textbook. Also, for explanations that are more in-depth, the book comes in handy.
MIT offers this course in 2 parts via edX. While 6.00.1x is is an introduction to computer science as a tool to solve real-world analytical problems, 6.00.2x is an introduction to computation in data science. For a general look and feel of the course, this OCW link may be a good starting point. It contains material including video lectures and problem sets that are closely related to 6.00.1x and 6.00.2x.
Each week’s material of 6.00.1x consists of 2 topics, followed by a Problem Set. Problem Sets account for 40% of your grade. Video lectures are followed by finger exercises that can be attempted any number of times. Finger exercises account for 10% of your grade. The Quiz (kind of like a mid-term exam) and the Final Exam account for 25% each. The course is of 8 weeks duration and covers the following topics (along with corresponding readings from John Guttag’s textbook).
From the questions posted on forums, it was apparent that the section of this course that most people found challenging, was efficiency and orders of growth – and in particular, the Big-O asymptotic notation and problems on algorithmic complexity.
Lectures on Classes, Inheritance and Object Oriented Programming (OOP) were covered really well in over 100 minutes of video time. I enjoyed the problem set that followed, requiring the student to build an Internet news filter alerting the user when it noticed a news story that matched that user’s interests.
The final week had lectures on the concept of Trees, which were done hurriedly when compared to the depth of detail the instructor had earlier gone to, while explaining concepts from previous weeks. However, this material was covered quite well in Guttag’s textbook and the code for tree search algorithms was provided for perusal as part of the courseware.
At the end of the course, there were some interesting add-on videos to tickle the curiosity of the learner on the applications of computation in diverse fields such as medicine, robotics, databases and 3D graphics.
The Wiki tab for this course (in the edX platform) is laden with useful links to complement each week of lectures. I never got around to reading those, but I’m going through them now, and they’re quite interesting. It’s a section that nerds would love to skim through.
I learnt a great deal from this course (scored well too) putting in close to 6-hours-a-week of study. It is being offered again on August 26, 2015. In the mean time, I’m keeping my eyes open for MIT’s data science course (6.00.2x) which is likely to be offered in October, in continuation to 6.00.1x.