This is a very short post that will be very useful to help you quickly set up your COVID-19 datasets. I’m sharing code at the end of this post that scrapes through all CSV datasets made available by COVID19-India API.
Copy paste this standalone script into your R environment and get going!
There are 15+ CSV files on the India COVID-19 API website. raw_data3 is actually a live dataset and more can be expected in the days to come, which is why a script that automates the data sourcing comes in handy. Snapshot of the file names and the data dimensions as of today, 100 days since the first case was recorded in the state of Kerala —
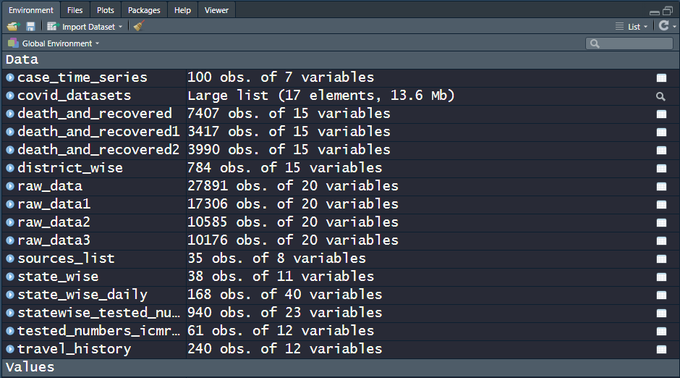
My own analysis of the data and predictions are work-in-progress, going into a Github repo. Execute the code below and get started analyzing the data and fighting COVID-19!
| rm(list = ls()) | |
| # Load relevant libraries ----------------------------------------------------- | |
| library(stringr) | |
| library(data.table) | |
| # ============================================================================= | |
| # COVID 19-India API: A volunteer-driven, crowdsourced database | |
| # for COVID-19 stats & patient tracing in India | |
| # ============================================================================= | |
| url <- "https://api.covid19india.org/csv/" | |
| # List out all CSV files to source -------------------------------------------- | |
| html <- paste(readLines(url), collapse="\n") | |
| pattern <- "https://api.covid19india.org/csv/latest/.*csv" | |
| matched <- unlist(str_match_all(string = html, pattern = pattern)) | |
| # Downloading the Data -------------------------------------------------------- | |
| covid_datasets <- lapply(as.list(matched), fread) | |
| # Naming the data objects appropriately --------------------------------------- | |
| exclude_chars <- "https://api.covid19india.org/csv/latest/" | |
| dataset_names <- substr(x = matched, | |
| start = 1 + nchar(exclude_chars), | |
| stop = nchar(matched)- nchar(".csv")) | |
| # assigning variable names | |
| for(i in seq_along(dataset_names)){ | |
| assign(dataset_names[i], covid_datasets[[i]]) | |
| } | |
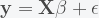 ,
,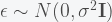
 is the
is the 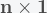 outcome variable and
outcome variable and  is the
is the  data matrix of independent predictor variables (including a vector of ones corresponding to the intercept). The ordinary least squares (OLS) estimate for the vector of coefficients
data matrix of independent predictor variables (including a vector of ones corresponding to the intercept). The ordinary least squares (OLS) estimate for the vector of coefficients  is:
is:
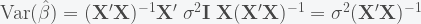
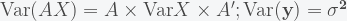
 and with these, one can compute the t-statistics and their corresponding p-values.
and with these, one can compute the t-statistics and their corresponding p-values. – for the full model with all predictors
– for the full model with all predictors – for the partial model (
– for the partial model (![\mathbf{y} = \mathbf{\mu} + \mathbf{\nu}; \mathbf{\mu} = \mathop{\mathbb{E}}[\mathbf{y}]; \mathbf{\nu} \sim N(0, \sigma_0^2 \mathbf{I})](https://s0.wp.com/latex.php?latex=%5Cmathbf%7By%7D+%3D+%5Cmathbf%7B%5Cmu%7D+%2B+%5Cmathbf%7B%5Cnu%7D%3B+%5Cmathbf%7B%5Cmu%7D+%3D+%5Cmathop%7B%5Cmathbb%7BE%7D%7D%5B%5Cmathbf%7By%7D%5D%3B+%5Cmathbf%7B%5Cnu%7D+%5Csim+N%280%2C+%5Csigma_0%5E2+%5Cmathbf%7BI%7D%29+&bg=f5f6f7&fg=444444&s=1&c=20201002) ) with the outcome observed mean as estimated outcome
) with the outcome observed mean as estimated outcome










